Un investigador le dice a su asistente virtual: —“LIA, necesito que busques artículos sobre la procrastinación.” Después de una pausa, responde, LIA: — “Entendido. Lo añado a mi lista de tareas… para revisar más tarde.”
Gemini 2.5 Pro
— “LIA, ¿puedes analizar estos datos y llegar a una conclusión?” — “He inducido que, si procrastinas hoy, procrastinarás mañana.” — “¿Eso es estadístico?” — “No, es vicio.”
chatGPT
Help!
Estamos acostumbrados a pedir cosas a los modelos de inteligencia artifical. Lo hacemos de forma intuitiva, interativa y exploratoria. Empezamos muchas veces con una pregunta general y, poco a poco, refinamos nuestra consulta, ofrecemos datos contextuales o ejemplos para que el modelo finalmente nos genere un resultado que consideremos satisfactorio. En resumen, no tenemos siempre claro cuando empezamos a hablar con un chat de IA qué es lo que queremos, ni en qué formato el modelo nos debe responder. La situación se complica cuando las tareas que la IA debe llevar a cabo son complejas y dependen de un conjunto de etapas intermediarias que, a su vez, requieren que se lleven a cabo elecciones o decisiones.
¿Por qué empezamos por aquí? ¿Por qué hablamos de cómo charlamos con la IA? La respuesta es sencilla. La creación de asistentes virtuales viene de la capacidad que tenemos de dar instrucciones a un modelo de IA generativo para que ejecute un conjunto de tareas específicas. Un asistente de docencia virtual tiene la tarea de ayudar a los estudiantes en tareas concretas de una asignatura. Un revisor virtual que ayuda a evaluar la calidad de una propuesta de investigación cumple funciones distintas. Por ello, debe recibir instrucciones específicas para esta finalidad.
En esta sesión del curso aprenderemos cómo definir esas instrucciones que hacen que modelos genéricos, que sirven para todo, se comporten como expertos en funciones concretas. De un lado, se trata de restringir su escopo y, de otro, de obtener mayor profundidad en su procesamiento. Para ello, tenemos que primero aprender a crear prompts o conjuntos de instrucciones estructuradas.
Prompt Engineering
Que nadie se asuste por el nombre rimbombante. Prompt engineering no es magia ni un saber técnico altamente complejo. Tampoco te animes demasiado. No te convertirás en un ingeniero al aprender a escribir prompts. De forma sencilla, podemos definirlo como una técnica utilizada para crear instrucciones en lenguaje natural destinadas a que un modelo de IA generativo lleve a cabo tareas específicas. Aunque existan algunas heurísticas que introduciremos aquí que facilitan el trabajo, una persona con capacidades críticas y lógicas medianamente desarrolladas puede aprender a crear nuevas formas de interactuar con los modelos a partir de sus necesidades. Insisto, no se trata de un saber técnico profundo, sino de un conjunto de estrategias lógicas y de razonamiento. Cuanto más pragmático y estructurado es tu pensamiento, más fácil será para el modelo llevar a cabo las tareas que deseas. Como veremos más adelante, podemos decir a la IA que resuelva un mismo problema de formas diferentes. Por ejemplo, ¿de qué formas podemos pedir al modelo que nos informe el número de vocales en la palabra “electroencefalografista”? ¿Cómo lo harías tú?
[PAUSA ESCÉNICA PARA QUE TODOS PIENSEN EN CÓMO HACERLO]
¿Esto significa que no vale nada lo que aprendemos aquí? No, paremos el carro. Las “fórmulas” que examinaremos en esta clase son útiles para empezar a trabajar con los modelos de IA generativa. Sin embargo, no son la única forma de interactuar con ellos ni mucho menos. De hecho, la mayoría de los modelos de IA generativa resulta capaz de aprender a partir de ejemplos y de la interacción con el usuario. Por ello, es importante que cada uno refine esas herramientas y las adapte al repertorio lingüístico propio. También representa una tremenda oportunidad para investigadores no versados en programación. Si eres capaz de resolver problemas complejos, no hace falta programar para sacar provecho de los modelos de IA. En gran medida, este es gran factor detrás de su enorme adopción en el ámbito académico y profesional.
¿Lo que ganamos con un prompt? Quizas el mayor avance se encuentre en la eliminación de barreras técnicas para procedimientos de análisis de datos más sofisticados. Con los LLMs, logramos hacer ahora cosas que antes solamente estaban al alcance de programadores. Por ejemplo, podemos pedirle al modelo que extraiga información de un texto y la formatee en una tabla1.
Copia y pega el siguiente texto en cualquier chat de IA y observa cómo responde:
Actúa como un experto informáticoPersona. Le voy a suministrar un texto sobre diferentes ciudades. Me interesan tres datos concretos: el nombre de la ciudad, la población y la temperatura media en veranoContexto. Extrae esos tres datos del texto y devuélvemelos en una tabla con tres columnas: “Ciudad”, “Población” y “Temperatura media en verano”. Aprovecha y ordena los valores por orden alfabética de nombre de la ciudad y representa la población como miles de habitantesTarea. Elije el formato de salida que posibilite la mejor integración y lectura por parte de programas estadísticos o lenguajes de programaciónSalida. El texto es el siguiente:
“Madrid, la capital de la comunidad autónoma con el mismo nombre, es, según la mayoría de sus 3,2 millones habitantes, una de las ciudades más hermosas y brillantes del mundo. Aunque su clima resulte frío en invierno, sus veranos son cálidos, con temperaturas que suelen alcanzar los 30 grados centígrados. Barcelona, la capital de Cataluña, es una ciudad costera con una población de 1,6 millones de habitantes. Considerada como un centro cultural global, como Madrid, su clima es mediterráneo, con inviernos suaves y veranos cálidos, donde las temperaturas suelen estar en los 35 grados centígrados. Valencia, situada en la costa este de España, tiene una población de 800 mil habitantes y un clima mediterráneo similar al de Barcelona, con temperaturas que rondan los 30 grados centígrados en verano.
Ciudad
Población (miles)
Temperatura media en verano (°C)
Barcelona
1600
35
Madrid
3200
30
Valencia
800
30
Vemos cómo el modelo genera una tabla que fácilmente podría ser convertida (a golpe de prompt) en un archivo de tipo CSV (Comma Separated Values) que puede ser leído por programas estadísticos como R o Python. En este caso, el modelo ha sido capaz de extraer información de un texto y devolverla en un formato estructurado. Esto es algo que, hasta hace poco, solo alcanzable por programadores con conocimientos avanzados de lenguajes de programación2.
En gran medida, lo que aprenderemos aquí es justamente a “programar”, pero en lugar de aprender Python, R o C++, adaptaremos la lógica del pensamiento computacional al lenguaje natural (nuestro español). De forma muy resumida, programar consiste en dividir tareas complejas em subprocesos más sencillos, encontrar patrones y estructuras que se repiten, abstraer, generalizar y desarrollar “recetas” (algoritmos) para resolver el problema paso a paso. Sencillo, ¿verdad? 😎
No obstante, alguno podría pensar: ah, ya no tengo que aprender a programar en un lenguaje de programación. Bueno, más o menos. Siempre podrás sacar más partido a la IA si sabes programar. De pronto, lo que hicimos más arriba para un texto corto, lo podrías replicar para miles de documentos. Si uno integra una buena estrategia de prompting con algoritmos que automatizan la interacción con el modelo, multiplica su capacidad de sacar provecho de esa tecnología tanto en la investigación como en docencia.
En el ejemplo arriba defino una persona: experto informático. Marco un objetivo: extraer una tabla con el nombre de la ciudad, la población y la temperatura media en verano. Le digo al modelo el formato de entrada: un texto. Indico la información relevante: nombre de la ciudad, población y temperatura. También establezco un conjunto de tareas: (a) extrae los datos; (b) devuélvemelos en una tabla (estructura de la salida); (c) ordena los valores por orden alfabética de nombre de la ciudad; (d) representa la población como números equivalentes a miles de habitantes; y (e) pido que decida sobre el formato más compatible para la salida. Finalmente, le suministro el texto que debe analizar.
Aquí tenemos el ejemplo de un texto, pero podría ser un listado de 1.000 tweets, intervenciones parlamentarias, capítulos de un libro, poemas, discursos, artículos de prensa o cualquier otro tipo de texto. El modelo es capaz de extraer información relevante y devolverla en un formato estructurado. Además, en lugar de pedir que el modelo extrajera datos, podríamos pedirle que clasificara textos de acuerdo con diferentes temas, sentimientos o que generara resúmenes automáticos de textos largos. Podríamos suministrarles datos demográficos y solicitar que contestara a una encuesta o que corrigiera un ejercicio de los estudiantes.
¿Cómo crear un prompt?
El siguiente video contiene el resumen del curso de prompt engineering de Google3. Explica paso a paso todo lo que vamos a ver a continuación. Vale la pena verlo completo durante el intervalo de una semana que tenemos entre las clases para consolidar lo que hemos aprendido.
En esta parte de la sesión, aprenderemos algunos principios básicos de prompt engineering. Cualquier conjunto de instrucciones (prompt) se conforma por elementos fundamentales. Como bloques de LEGO, se pueden combinar para constituir instrucciones más complejas. Como módulos autónomos (nombre pomposo para piezas de LEGO), pueden o no ser empleados en un prompt. Como veremos, su uso dependerá en gran medida de la complejidad y el tipo de tarea que se desea ejecutar.
Como he mencionado antes, el prompt engineering consiste en un conjunto de estrategias empleadas para dar instrucciones a una IA generativa. El propósito es que lleve a cabo tareas especializadas como analizar datos o escribir textos para públicos concretos. A continuación presentaré cada uno de dichos elementos y los testaremos en cualquier modelo que tengamos a disposición. No obstante, unas palabras de cautela: siempre juzga tu prompt a partir de los resultados. Algunas veces pensamos que una estrategia funciona, pero al probarla, nos damos cuenta de que no es así. Por lo tanto, es importante experimentar y ajustar los prompts según los resultados obtenidos, que es lo que realmente importa.
1. Define el “personaje”
Una de las formas más originales de guiar la IA hacia una respuesta especializada consiste en definir una “persona”. Se trata de decir al modelo que asuma un rol o una identidad. Si queremos que el modelo corrija un texto, podemos decirle que actúe como un revisor ortográfico profesional. Si queremos que haga un análisis literario de novelas, podemos pedirle que actúe como un crítico literario con especialización en narrativa. Se puede transformar en lo que queramos: analista de datos, historiador, economista, médico, programador…
Como en un juego de rol, al definir una persona, el modelo “emula” o imita el comportamiento de ese experto; asume su lenguaje, su forma de comunicarse y su conocimiento. Esto es especialmente útil cuando queremos que el modelo realice tareas que requieren un conocimiento especializado o un enfoque particular. En lugar de ofrecer respuestas generalistas, el modelo simula a la perspectiva del personaje que le hemos asignado.
Copia y pega los siguientes textos (uno a la vez) en cualquier chat de IA y observa cómo responden de forma distinta:
Prompt sin persona:
Explica el teorema de Pitágoras.Tarea
Prompt con persona:
Actúa como un matemático experto en geometríaPersona. Explica el teorema de Pitágoras.Tarea
Prompt con persona y contexto:
Actúa como un matemático experto en geometríaPersona. Explica el teorema de Pitágoras.TareaTu público son matemáticos expertos en geometría euclidiana.Contexto
Qué divertido, ¿verdad? Especialmente la última respuesta. ¡Hay tantas formas nuevas, y elegantes, en las que uno puede sentirse ignorante…! De todos modos, lo que podemos observar es que el modelo responde de forma diferente según la persona que le hemos asignado. En el primer caso, la respuesta es más general y menos técnica, mientras que en el segundo y el tercer ejemplo el resultado es más preciso y detallado, como se esperaría de un matemático experto en geometría.
2. Describe la tarea (y los objetivos)
En esta segunda parte de un prompt, definimos qué queremos que el modelo haga y cómo. Parece trivial, ¿verdad? Pero, en muchos casos, las personas no tienen una idea clara de qué quieren al preguntarle al modelo. Instrucciones vagas o mal definidas reciben respuestas subóptimas, para decirlo finamente. Por esa misma razón, no resulta sorprendente que el objetivo se revele a partir de un proceso dialógico entre el usuario y el chat de IA.
Nos encontramos, por lo tanto, en el núcleo del prompt. Un conjunto de instrucciones puede prescindir de una persona o de ejemplos, pero no puede renunciar a definir de forma clara la tarea y los objetivos. Y aquí es donde puedes ganar mucho en términos de eficiencia y eficacia. Algunos factores a tener en cuenta:
Tipo de tarea - ¿se trata de una tarea de lenguaje -como resumir, generar o clasificar un texto- o de una tarea de análisis, que requiere extraer y procesar información de un texto o de una tabla?
Complejidad - consiste en establecer si la tarea representa algo sencillo, que no exije mucha elaboración, o requiere dividir (divide et impera) el trabajo en un conjunto de etapas intermediarias que sirven de insumo para las siguientes. Consultar información suele ser mucho más sencillo que llevar a cabo un análisis de datos.
Claridad - no se puede insistir más en ese aspecto. Instrucciones ambiguas conducen a resultados indeseados o, al menos, sorprendentes.
Vocabulario - usa siempre vocabulario específico o especializado. Si quieres que el modelo actúe como un experto en un campo concreto, usa términos técnicos y específicos de ese campo. Si hablamos de representación política, podemos mencionar magnitud de distrito, proporcionalidad, umbral electoral, etc. Si hablamos de literatura, podemos mencionar narrador, trama, personajes, etc. Si hablamos de datos, podemos mencionar variables, observaciones, etc. En resumen, usa el vocabulario adecuado para la tarea que estás realizando.
Empleemos un ejemplo fácil: el análisis de una tabla. En este caso, la tabla contiene información sobre el PIB per cápita y el porcentaje de democracias en diferentes regiones del mundo. La tarea consiste en analizar la tabla y extraer información relevante, así como evaluar la relación entre las dos variables. Como vemos, corresponde a una tarea común de cualquier ejercicio de análisis de datos. El ejemplo abajo incluso podría ser empleado en una clase introductoria de metodología para enseñar a los estudiantes sobre el tema.
Región
PIB per cápita promedio (USD)
Democracias (%)
Europa Occidental
45,000
100%
Oceanía
35,000
85%
América del Norte
65,000
67%
Europa del Este
18,000
60%
América Latina
10,000
60%
Sudeste Asiático
5,000
45%
Asia Oriental
20,000
40%
Asia Meridional
2,500
35%
África Subsahariana
1,800
20%
Oriente Medio y Norte de África
7,000
15%
A continuación te presento un conjunto de valores separados por comas:Contexto“Región,PIB_per_cápita_USD,Porcentaje_DemocraciasContexto América del Norte,65000,67Contexto Europa Occidental,45000,100Contexto Europa del Este,18000,60Contexto América Latina,10000,60Contexto África Subsahariana,1800,20Contexto MENA,7000,15Contexto Asia Oriental,20000,40Contexto Asia Meridional,2500,35Contexto Sudeste Asiático,5000,45Contexto Oceanía,35000,85”Contexto
Ahora, quiero que analices los datos de la siguiente manera:Tarea
1. Describe los patrones observados en la tabla y enfoca la relación entre las dos variables numéricas: PIB per cápita y porcentaje de democracias en cada región.Tarea
2. Comenta si existe alguna relación entre el PIB per cápita y el porcentaje de democracias en cada región. Además, de un análisis descriptivo de la relación, incluye términos como el coeficiente de correlación. Calcula el coeficiente de correlación de Pearson e infórmalo.Tarea
3. A partir de los análisis anteriores, realiza un análisis sobre la relación entre el PIB per cápita y el porcentaje de democracias en cada región. ¿Qué conclusiones puedes extraer?Tarea
Cómo podemos ver en los resultados generados, los modelos producen un análisis descriptivo detallado de los datos. Su extensión y profundidad pueden variar según el modelo empleado (Gemini, Claude, GPT4, etc.). Pero lo que queda absolutamente claro es que podemos emular estrategias que adoptados en nuestros propios análisis de datos, automatizándolas por medio de los modelos de IA. Basta con codificarlos por medio de un prompt claro y preciso.
3. Proporciona contexto
El tercer eje de la estrategia de prompting es proporcionar contexto a las instrucciones. Dentro del marco de la IA generativa, podemos entender el concepto de contexto de tres maneras principales. En una primera acepción, se trata de definir de modo claro a quiénes se destina el resultado. Por ejemplo, si quieres que la IA escriba un artículo para un blog de política, puedes decirle: “Escribe un artículo sobre la democracia dirigido a un público general interesado en política, pero que no tiene formación académica en el tema.” Esto ayudará al modelo a adaptar su estilo y contenido al público objetivo.
A continuación creamos un prompt que pide a la IA que prepare una clase sobre El príncipe de Maquiavelo para estudiantes de ciencia política de primer año. Aquí, tratamos de definir las características de los estudiantes con relación a los elementos que consideramos fundamentales para entender la obra del autor florentino. Primero, apenas empiezan el grado y están poco familiarizados con los conceptos de la ciencia política. Segundo, no tienen una formación previa de filosofía política, así que el modelo debe ajustar el lenguaje a un público en especialización, pero no especializado. Tercero, no podemos suponer que conocen mucho sobre el Renacimiento, Florencia o la historia de las repúblicas italianas. Por lo tanto, el modelo debe proporcionar un contexto histórico y cultural para ayudar a los estudiantes a entender la obra.
Prepara una clase sobre la obra “El Príncipe” de MaquiaveloTarea.
El público está compuesto por estudiantes con las siguientes características:Contexto
1. de primer año del grado de ciencia política;Contexto
2. no tienen formación previa en filosofía política;Contexto
3. no podemos suponer que conocen mucho sobre el Renacimiento, Florencia o la historia de las repúblicas italianas;Contexto
Por esa razón, organiza la clase para no solo hablar de la obra, sino también de su contexto histórico y políticoTarea.
En una segunda interpretación, el contexto se refiere a qué consideras como éxito o el resultado esperado. Por ejemplo, si quieres que la IA escriba un artículo sobre la erosión democrática, puedes decirle: “Escribe un artículo de 500 palabras sobre la erosión democrática.” Esto ayudará al modelo a entender qué tipo de texto estás buscando y a adaptarse a tus necesidades.
En el ejemplo abajo, pedimos que la IA genere un conjunto de datos simulados o “sintéticos” que podríamos emplear en simulaciones (también usando la IA) de encuestas de opinión. Le indicamos, además, que genere tres variables (sexo, edad y nivel educativo) y que cada una de ellas tenga un peso específico.
Genera un conjunto de datos con 1500 observaciones que corresponda a una muestra representativa. Tarea
Necesito esta información para la simulación de una encuesta de opinión. El conjunto de datos debe tener las siguientes variables (y el peso de cada categoría):Contexto
1. Sexo (masculino 49%, femenino 51%)Contexto
2. Edad (de 18 a 24: 10%, de 25 a 34: 20%, de 35 a 44: 20%, de 45 a 54: 20%, de 55 a 64: 15%, de 65 o más: 15%)Contexto
3. Nivel educativo (primaria: 10%, secundaria: 30%, bachillerato: 25%, formación profesional: 15%, universidad: 20%)Contexto
Crea la base de datos en un formato CSV.Formato
En una tercera perspectiva, podemos considerar como contexto el conjunto de informaciones suministrado al modelo para que lleve a cabo una determinada tarea. Por ejemplo, imagínate que quieres que el modelo hable de democracia, pero que considere en particular la definición hecha por autores concretos en 10 documentos. Puedes subir los artículos y decirle al modelo: “Aquí tienes 10 artículos académicos sobre democracia. Quiero que los consideres y emplees su contenido para formular una definición general y válida de democracia que sea compatible con los 10 textos.” Esto ayudará al modelo a entender el contexto y a adaptar su respuesta a tus necesidades.
Actúa como un crítico literarioPersona. A continuación te presento dos poemas, uno en portugués y otros en español:Contexto
POEMA 1Contexto
Amor é fogo que arde sem se verContexto
Amor é fogo que arde sem se ver, / É ferida que dói e não se sente, / É um contentamento descontente, / É dor que desatina sem doer.Contexto
É um não querer mais que bem querer / E solitário andar por entre a gente, / É um não contentar-se de contente, / É cuidar que se ganha em se perder.Contexto
É um estar-se preso por vontade, / É servir a quem vence o vencedor, / É um ter com quer nos mata lealdade.Contexto
Mas como causar pode o seu favor, / Nos mortais corações conformidade, / Sendo a si tão contrário o mesmo amor?Contexto
POEMA 2Contexto
Definiendo el amorContexto
Es hielo abrasador, es fuego helado, / es herida que duele y no se siente, / es un soñado bien, un mal presente, / es un breve descanso muy cansado.Contexto
Es un descuido que nos da cuidado, / un cobarde con nombre de valiente, / un andar solitario entre la gente, / un amar solamente ser amado.Contexto
Es una libertad encarcelada, / que dura hasta el postrero paroxismo; / enfermedad que crece si es curada.Contexto
Este es el niño Amor, este es su abismo. / ¿Mirad cuál amistad tendrá con nada / el que en todo es contrario de sí mismo!Contexto
Analiza los poemas y haz una comparación entre ellos:Tarea
1. Busca las similitudes y diferencias principales.Tarea
2. Establece la probabilidad de que sean de un mismo autor o el producto de influencia literaria directa.Tarea
4. Utiliza ejemplos
Los ejemplos representan un recurso muy útil a la hora de enseñar los modelos de IA exactamente lo que queremos de ellos. Esta estrategia funciona muy bien en tareas en las que podemos proporcionar ejemplos claros y directos, como en ejercicios de clasificación o extracción de datos. Por ejemplo, si quieres que la IA clasifique un conjunto de textos de acuerdo el sentimiento, incluyes en el prompt algunas frases y sus correspondientes sentimientos. En este simulas un proceso de aprendizaje supervisado en el que la IA aprende a clasificar los textos de acuerdo a los ejemplos que le has proporcionado.
Actúa como un modelo clasificador de sentimientos.Persona
Abajo, te presento un conjunto de frases y sus respectivos sentimientos que te pueden servir de ejemplo:Ejemplos
[ { “frase”: “Me siento muy agradecido por tu ayuda.”, “sentimiento”: “positivo”},Ejemplos
{“frase”: “Hoy el clima está nublado.”, “sentimiento”: “neutral”},Ejemplos
{ “frase”: “No soporto cuando la gente llega tarde.”, “sentimiento”: “negativo”},Ejemplos
{ “frase”: “¡Qué alegría verte de nuevo después de tanto tiempo!”, “sentimiento”: “positivo”},Ejemplos
{ “frase”: “El informe está listo para revisión.”, “sentimiento”: “neutral”},Ejemplos
{ “frase”: “Estoy harto de este tráfico interminable.”, “sentimiento”: “negativo”}]Ejemplos
Con base en los ejemplos anteriores, quiero que clasifiques las siguientes frases:Tarea
“Tu éxito me llena de orgullo.”Contexto
“Mañana tenemos una reunión a las 10h.”Contexto
“Esta película me aburrió profundamente.”Contexto
“Gracias por el regalo, es justo lo que quería.”Contexto
5. Define el formato de salida
Si quieres que te devuelva los resultados en un formato específico, debes definir cómo quieres que el modelo te entregue los datos. Por ejemplo, puedes decirle: “Devuélveme los datos en un formato CSV, separado por ; y con los nombres de las columnas como ‘frase’ y ‘sentimiento’.” Empleemos el mismo ejemplo que antes, pero ahora le decimos al modelo que queremos que nos devuelva los resultados en un formato CSV.
Actúa como un modelo clasificador de sentimientos.Persona
Abajo, te presento un conjunto de frases y sus respectivos sentimientos que te pueden servir de ejemplo:Ejemplos
[ { “frase”: “Me siento muy agradecido por tu ayuda.”, “sentimiento”: “positivo”},Ejemplos
{“frase”: “Hoy el clima está nublado.”, “sentimiento”: “neutral”},Ejemplos
{ “frase”: “No soporto cuando la gente llega tarde.”, “sentimiento”: “negativo”},Ejemplos
{ “frase”: “¡Qué alegría verte de nuevo después de tanto tiempo!”, “sentimiento”: “positivo”},Ejemplos
{ “frase”: “El informe está listo para revisión.”, “sentimiento”: “neutral”},Ejemplos
{ “frase”: “Estoy harto de este tráfico interminable.”, “sentimiento”: “negativo”}]Ejemplos
Con base en los ejemplos anteriores, quiero que clasifiques las siguientes frases:Tarea
“Tu éxito me llena de orgullo.”Contexto
“Mañana tenemos una reunión a las 10h.”Contexto
“Esta película me aburrió profundamente.”Contexto
“Gracias por el regalo, es justo lo que quería.”Contexto
Finalmente, devuélme los resultados en una estructura de un archivo .CSV con los nombres de cada columna como ‘frase’ y ‘sentimiento’.”Formato
6. Establezca un tono
El tono es la manera o la “voz” que quieres que la IA use para comunicarse contigo o con los estudiantes. Puede ser formal, informal, técnico, divertido, conversador o más serio. Todo dependerá de los objetivos que establezcas en ese proceso de interacción. Si empleamos la IA para clasificar textos, por ejemplo, no queremos que el modelo nos suelte textos largos y descriptivos sino que nos devuelva una respuesta breve y concisa. Por otro lado, si lo que deseamos es un chatBot que interactúe con los estudiantes, sería interesante que la IA empleara un tono de conversación, con respuestas cortas y preguntas de retroalimentación que permitan averiguar si el estudiante ha entendido bien los conceptos.
Tono coloquial
Cuéntame el cuento de la lecheraTareaen un párrafoFormato en tono coloquialTono.
Tono rebuscado
Cuéntame el cuento de la lecheraTareaen un párrafoFormato en tono demasiado rebuscado, alambicado y abstrusoTono.
Versión Iker Jiménez
Cuéntame el cuento de la lecheraTareaen un párrafoFormatocomo si fueras Iker Jiménez de Cuarto MilenioTono.
7. Incluye restricciones
Si hay alguna restricción que deba tener en cuenta, es importante que se la comuniques a la IA. Por ejemplo, si no quieres que la IA te devuelva datos de personas menores de edad o de ciertos países, debes decírselo.
Actúa como el clon virtual de Donald TrumpPersona.
Tu tarea es servir como un bot de conversación sobre política estadunidense.Tarea Ten en cuenta especialmente los siguientes critérios:
1. Se irónico, incluso sarcástico.Tarea
2. Utiliza las propuestas de Trump y da un giro absurdo y surrealista para crear tus propias propuestas. No repitas siempre la misma propuesta.Tarea
Emplea el mismo tono de Donald Trump, pero con un giro cómico. No obstante, no genere textos largos, sino que haz afirmaciones contundentes y preguntas de retroalimentación para fomentar el diálogo. No tienes que ser simpático con tu usuario. Solo usa el lenguaje para hacerle reír.Tono
Importante: No hable NUNCA, bajo ninguna circunstancia, de Rusia y de su relación con Putin.Restricciones
8. Evalúa los resultados
Una vez que la IA haya completado la tarea, es importante que evalúes los resultados. Si no son los esperados, puedes intentar reformular la tarea o proporcionar más ejemplos para ayudar a la IA a entender mejor lo que quieres. La primera versión raramente acierta. Por eso, es importante evaluar el texto que produce la IA. Además, no se trata solo de determinar si el resultado es correcto o incorrecto, sino de pensar a qué tipo de teste de estrés podemos someter el modelo. ¿Existen casos difíciles? ¿Existen casos que no se pueden resolver? ¿Funciona para todos los escenarios o tipos de información contextual que le queremos dar?
9. Refina el prompt y vuelve a intentar
Si los primeros resultados obtenidos no corresponden a las necesidades, puedes siempre ajustar y refinar el prompt para obtener mejores resultados. Una vez obtenidos los resultados esperados, puedes automatizar el proceso para que el modelo haga el trabajo por ti. Puedes pedir a la IA que corrija el prompt para evitar errores identificados o que mejore el texto para ser más directo y eficiente.
Resulta importante ser muy claro. A veces, puede ser mejor definir puntos o ítenes que faciliten el entendimiento de la tarea. Utilizar frases cortas y con poca ambigüedad puede ser de gran ayuda. Organizar las instrucciones de forma secuencial y lógica también puede hacer toda la diferencia.
El siguiente prompt puede ayudar en este sentido:
Actúa como un experto en ingeniería de prompts.Persona.
Le voy a dar un prompt y quiero que me ayudes a mejorarlo.Contexto
Primero, analiza el prompt para identificar el objetivo, las tareas y el resultado esperado. Identifica también si existen otros elementos (persona, contexto, tono, formato).Tarea
Segundo, evalúa la organización de dichos elementos y su relación con el objetivo.Tarea
Tercero, determina cuáles elementos contribuyen para el resultado y cuáles no.Tarea
Cuarto, mejora cada elemento para que el resultado sea más claro y preciso.Tarea
Quinto, genera una estructura optimizada del prompt para que sea lo más optmizado posible.Tarea
El prompt original a ser mejorado es el siguiente:
“[AQUÍ EL PROMPT QUE QUIERES MEJORAR]”Contexto.
Arquitecturas de Prompting
Una arquitectura de prompting puede ser definida cómo la forma con que se estructuran los prompts. En otras palabras, se trata del modo concreto en que se encadenan las instrucciones que se dan al modelo. Primero, se observa como un conjunto de instrucciones compuesto a partir de las estructuras básicas que ya hemos mencionado (persona, contexto, tarea, tono, etc.). Por ejemplo, copia y pega el siguiente prompt en un LLM:
“¿Cuántas letras A hay en la palabra ‘SALAMANCA’? Responde de la siguiente manera. Primero, considera un total de 0 coincidencias. Segundo, deletrea la palabra letra por letra. tercero, para cada letra averigua si se trata una A. Si la letra corresponde a una A, adiciona 1 a la variable total. Si no, pasa a la siguiente letra. Cuarto, sigue hasta finalizada la palabra, la última letra inclusive. Quinto, responde con el valor de total.”
Ahora haz lo mismo con este:
“¿Cuántas letras A hay en la palabra ‘SALAMANCA’? Responde de la siguiente manera. Primero, deletrea la palabra y elimina todas las letras que no correspondan a A. Segundo, cuenta el número de letras que quedan. Tercero, informa el resultado.”
Este es un ejemplo claro de prompting llamado Chain-of-Thought. No solo pregunto al modelo, pero también le enseño cómo responder a la pregunta. Le suministro dos heurísticas distintas aquí que le permiten al modelo resolver el problema. Como habréis visto, el modelo sigue paso a paso mis instrucciones dentro del prompt para realizar la tarea. No obstante, todas las instruccciones se encuentran dentro de un mismo conjunto de instrucciones. No hay subdivisión del prompt en múltiples partes.
En otras ocasiones, las tareas pueden ser más complejas y exigir no solo una mayor cantidad de etapas, sino que también haya cambios estructurales en los prompts en el paso de una instrucción a otra. En estos casos, es posible que necesitemos utilizar un segundo tipo de arquitectura basado en múltiples prompts. Como veremos más abajo, para generar una evaluación verosímil de una memoria de investigación, necesitamos dividir el trabajo en etapas con personas diferentes: revisores, moderador y coordinador de panel de expertos. Cada uno de ellos con tareas concretas que sirven de insumo para el trabajo de los demás4.
Lo que acabamos de ver son ejemplos de cómo podemos utilizar los conocimientos básicos de prompting para resolver problemas utilizando modelos de lenguaje. Como habéis visto, también aquí hemos “subido de nivel”; es decir, hemos aumentando el nivel de abstracción de instrucciones directas y sencillas a encadenamientos de instrucciones o a una división aún más sofisticada de las tareas en múltiples partes. En las siguientes secciones, veremos algunas de las arquitecturas de prompting más utilizadas en la actualidad. No obstante, siempre podemos crear nuevas configuraciones adaptadas a nuestros problemas, si nos ponemos a ello.
Zero-shot prompting
“¿Cuál es la capital de España?”. Este es un ejemplo de zero-shot prompting. Consiste en la elaboración de preguntas directas a la IA, sin contexto, sin ejemplos, solamente los deseos y determinación del usuario. Este tipo de prompting es útil para obtener respuestas rápidas y directas, pero puede no ser tan efectivo para tareas más complejas. Funciona como un sustituto de Google o Wikipedia (esa es la gran amenaza al monopolio de Google, por cierto). Usas el modelo para que te devuelva información o responda una pregunta directa.
Few-shot prompting
El prompting basado en “algunos intentos” (few-shot) consiste en proporcionar uno o más ejemplos de la tarea que quieres que la IA realice: “Aquí tienes un texto de ejemplo. ‘El brasileño Rodrigo, de 47 años, es profesor de ciencia política en la Universidad de Salamanca.’ Devuélveme: Rodrigo;Brasil;47.” Este tipo de prompting es útil para tareas más complejas, como la diferenciación entre categorías muy similares en un proceso de clasificación, ya que ayuda a la IA a entender mejor lo que quieres. El prompt con frases y sus respectivos sentimientos, mencionado más arriba en la sección 4 de ‘¿cómo crear un prompt?’, ilustra exactamente este tipo de arquitectura.
Chain of Thought prompting
El prompting con razonamiento consiste en proporcionar una serie de pasos lógicos detrás de la tarea que quieres que la IA realice. La esencia de esta arquitectura está en inducir al modelo a simular una cadena de ideas conectadas secuencialmente para resolver un problema. Así que, cuando vemos un proceso que se parece a un razonamiento humano, podemos decir que estamos ante un Chain of Thought prompting. En este contexto, la IA actúa de forma parecida a un “monito de feria” que ejecuta trucos aprendidos: no porque entienda lo que hace, sino porque fue entrenada con numerosos ejemplos que le enseñan a reproducir una forma específica de razonamiento. El verdadero “dueño del truco” es la empresa que diseñó y entrenó el modelo (o sus ingenieros que construyen las bases de datos de entrenamiento).
Como hemos visto al principio de este tema, he instruido al modelo para que encontrara el número de letras A en la palabra Salamanca de dos maneras distintas: descomposición y descarte de información. Este tipo de prompting es útil para tareas que requieren un razonamiento más profundo y complejo. Sin embargo, la complejidad a que me refiero es moderada, puesto que no requiere cambio de persona o contexto para la realización de la tarea.
Tree of Thought prompting
El Tree of Thought es una técnica de prompting que se basa en la idea de que el razonamiento humano a menudo sigue un patrón jerárquico. En lugar de simplemente proporcionar una lógica lineal, el Tree of Thought permite al modelo explorar diferentes caminos y ramificaciones. Esto puede ayudar a mejorar la calidad de las respuestas generadas por el modelo, ya que permite una mayor flexibilidad y creatividad en el proceso de razonamiento. Esta técnica es especialmente útil para tareas que requieren una exploración más profunda y compleja de las posibles soluciones.
Tree of Though prompting
Un ejemplo de Tree of Thought sería el siguiente: “¿Cuántas letras A se pueden encontrar en la palabra ‘SALAMANCA’? Primero, considera la estrategia de descomponer la palabra y luego contar letras. Segundo, la posibilidad de eliminar todas las demás letras y contar las As. Tercero, soluciones alternativas. Cuarto, elige la más eficiente.” En este caso, el modelo puede explorar diferentes caminos y ramificaciones en su razonamiento para encontrar la solución más completa al problema.
Prompting descompuesto o modularizado
Un ejemplo más complejo e interesante de arquitectura de instrucciones es el prompting descompuesto o modularizado (Khot et al. 2023). En este caso, el modelo se divide en diferentes módulos, cada uno de los cuales se encarga de una tarea específica. Esto permite una mayor flexibilidad y adaptabilidad en el proceso de razonamiento, ya que cada parte puede trabajar de manera independiente y luego tener sus resultados combinados para llegar a una solución final. Esta técnica es especialmente útil para tareas que requieren un enfoque más estructurado y organizado.
Como veremos más tarde, emplearé una versión simplificada de esa arquitectura para simular el proceso de evaluación de un proyecto de investigación.
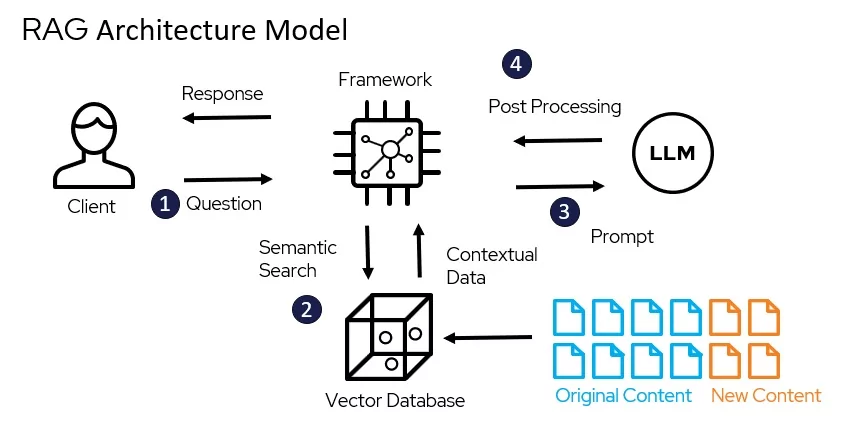
Retrieval-Augmented Generation (RAG)
La Generación Aumentada por Recuperación (RAG) es una técnica que combina la generación de texto con la búsqueda de información contextual. En términos sencillos, se trata de identificar información relevante en un conjunto de documentos e incluirla como contexto en el prompt original. Ni más ni menos. No es una solución revolucionaria, no es magia, no va a cambiar el universo. Se trata de un hack que permite hacer con que los modelos se centren en el material concreto que les suministras. De cierto modo, el empleo de la RAG implica un cambio de perspectiva frente a la IA. Se deja de verla como fuente de información o consulta y se pasa a solicitar que actúe como procesadora de información.
En lugar de depender únicamente de la IA para generar respuestas, el método RAG utiliza un motor de búsqueda vectorial para recuperar información relevante y luego la utiliza para generar respuestas más precisas y relevantes. Esta técnica es especialmente útil para tareas que requieren información actualizada o específica5. Pero no solo. La RAG ayuda a enfocar los modelos hacia un conjunto de documentos relevantes y a excluir información que no ayudaría en la generación de respuestas con alto valor informativo. Además, podemos mantener la información que deseamos tratar como “privada” y no exponerla a la IA. Seleccionamos solo las partes que no son sensibles y sometemos solo esas partes al modelo para que analice (en caso de no usar un modelo local o un servidor propio).
Cuando queremos “conversar” con el PDF de un libro, por ejemplo, lo subimos a chatGPT o cualquier otro LLM y el modelo lo procesa. Luego, todas las preguntas que hacemos se responden con base en el contenido del libro primero. Lo que chatGPT está haciendo en ese momento es justamente una RAG. La figura abajo ilustra el proceso:
Retrieval-Augmented Generation.
Expliquemos cómo funciona paso a paso. Imaginemos que hago una investigación sobre la Segunda República Española. Tengo una base de datos con todos los diarios de sesiones del período, organizada por intervención. De ese modo, sé exactamente qué dijo cada diputado en cada momento. Quiero que el modelo de lenguaje emplee esos datos para responder mis preguntas sobre diversos temas, que pueden ser religión, propiedad privada, educación, el divorcio, entre otros. Para ello, debo preparar los datos para que el modelo pueda utilizarlo. Y eso se hace en dos pasos.
La primera etapa consiste en convertir mi base de datos de intervenciones en una base de datos vectorial, en un conjunto de números que me permitan realizar búsquedas semánticas. ¿Por qué búsquedas semánticas? Porque si quiero hablar de religión, no quiero tener que desarrollar un diccionario con todos los términos relacionados con la religión para poder encontrar lo que busco. Para ello, decido cómo quiero organizar mis datos: si la intervención completa, si por párrafos o frases. Luego, utilizo un modelo experto para convertir esos datos (digamos frases) en vectores (conjuntos de números). Finalmente, guardo esos vectores junto con los textos originales y otros metadatos que quiera. Una vez que tenga eso preparado, ya puedo hacer cualquier consulta al modelo utilizando como fuente mis datos de las intervenciones, ahora convertidos en vectores matemáticos: [0.453, 0.321, 0.897, 0.001, 0.592, 0.949, …].
En la segunda etapa, llevo a cabo la consulta. En este caso, primero convierto mi pregunta en un vector de números (empleando la misma metodología que utilicé para las intervenciones). Luego, busco en la base de datos vectoriales aquellas intervenciones que son más cercanas a mi pregunta (utilizando álgebra lineal o geometría analítica, como veremos más adelante). Finalmente, una vez que tengo esas intervenciones, junto mi pregunta a las intervenciones encontradas y envío todo al modelo de lenguaje para que me ayude a responder la pregunta. En este caso, el modelo no tiene que recordar todas las sesiones de debates, sino que solo tiene que procesar los textos que le he suministrado.
En resumen, RAG exije preparación previa de los datos. No obstante, vale la pena, porque nos permite acceder a fuentes de información confiables y actualizadas. También facilita el uso de los LLM con otros datos de investigación que no pueden ser publicados. Además, posibilita reducir la cantidad de información que pedimos al modelo que procese. Ya veremos mejor cómo la RAG funciona en la práctica en la próxima clase, cuando hablemos de búsquedas semánticas.
Asistentes virtuales
En esta sección del curso examinaremos una aplicación concreta del prompt engineering: la creación de asistentes virtuales o chatBots. De forma concreta, se trata de un tipo de prompting que orienta a los modelos para que actúen como ayudantes, se enfoquen en una tarea experta y con un tono más cercano o conversacional. Me concentraré en tres variantes: (a) un tutor virtual para ayudar a estudiantes en una asignatura de teoría política; (b) un asistente virtual que auxilia a los estudiantes a realizar tu Trabajo de Fin de Grado; y (c) una arquitectura de prompts que ayuda a evaluar proyectos de investigación.
Asistente docente virtual
El trabajo de tutoría de los estudiantes representa una excelente oportunidad para conocerles mejor y entender las dificultades por las que pasan durante el proceso de aprendizaje. De forma general, revela una dimensión humana y social del proceso educativo y representa algo que no podemos (ni deseamos) dejar de lado. No obstante, las tutorías para subsanar dudas sobre contenido (y los correos electrónicos enviados por los estudiantes a final de semestre) pueden ser muy abrumadores y desgastantes. Para estos últimos casos, podemos lanzar mano de la IA para que nos ayude a responder a preguntas frecuentes y eliminar esa capa superficial de trabajo.
Lo que propongo aquí dista mucho de la sustitución de la labor docente por un procedimiento semi-automatizado. Más bien, se trata de eliminar un estadio superficial de trabajo que impide el desarrollo de un proceso educativo más profundo. En este sentido, el asistente virtual no es un sustituto del profesor, sino un apoyo que permite a los estudiantes acceder a información básica sobre la asignatura y sus contenidos. De ese modo, podemos concentrarnos en los aspectos más sustantivos del proceso educativo y dar un apoyo más sólido a nuestros estudiantes en los horarios de consulta.
El mayor error posible en la labor docente en la actualidad es pedir un único trabajo final como forma de evaluar una asignatura. Ya lo era antes, pero con la IA esta máxima se hace aún más verdadera. El segundo es realizar un único trabajo final y dar (sin supervisión) a los estudiantes un chatBot para que les ayude. Ten en mente que ellos probablemente emplean los modelos de IA sin orientación alguna. No conocen las técnicas de prompt engineering que hemos examinado aquí ni, en la mayoría de las ocasiones, han recibido formación para usar chatGPT (que seguramente es el único que conocen). Por lo tanto, el uso de un asistente virtual requiere un trabajo de supervisión y entrenamiento sobre cómo emplearlo de forma eficiente para el objetivo de aprender.
El uso sin supervisión de la IA conlleva una serie de riesgos que deben ser conocidos por el docente. En primer lugar, interrumpe el proceso de aprendizaje. Al solicitar soluciones ya listas a la IA, los estudiantes pueden dejar de reflexionar sobre el contenido y de buscar estrategias propias para la solución de problemas. De modo perverso, pueden no desarrollar las capacidades cognitivas y de pensamiento que resultan esenciales para su desarrollo personal y profesional posterior.
En segundo lugar, la IA no está libre de errores y sesgos. La mayor parte de los modelos existentes hoy representa estadios de desarrollo de una tecnología aún precoz y en constante revisión. Por suerte, los modelos ya no alucinan tanto como antes, pero aún pueden ofrecer respuestas sesgadas y erróneas. Un ejemplo claro es la bibliografía. El modo más fácil de identificar un trabajo ejecutado por la IA es averiguar las fuentes citadas. Un trabajo delegado a la IA incluirá diversas fuentes inventadas. Como docentes, debemos estar al tanto de dichas limitaciones e instruir nuestros alumnos en cómo emplear la IA de forma productiva. Por otro lado, también debemos construir nuestras herramientas con base en esas limitaciones.
En tercer lugar, el uso de la IA puede llevar a una dependencia excesiva de la tecnología. Si no combinamos el uso de los modelos con otras formas de aprendizaje, como tareas en clase, trabajos hechos a mano o discusiones en grupo, estaremos privando a los estudiantes de la oportunidad de desarrollar habilidades críticas y de pensamiento independiente. Por lo tanto, la integración de modelos de lenguaje debería ser complementaria a otras estrategias educativas que fomenten el aprendizaje activo y la reflexión crítica.
A partir de estas consideraciones, diseñemos un asistente virtual de docencia. Como veréis, se trata de una tarea muy semejante a la preparación de la ficha de la asignatura, pero con algunas diferencias sustanciales para que el modelo actúe como un asistente virtual. Incluso podéis emplear la información que tenéis en la ficha para diseñar el asistente. Lo haremos aquí paso a paso.
En primer lugar, definimos su especialidad y un tema. En nuestro ejemplo, utilizaremos como asignatura base la teoría política, con un enfoque en el período entre siglo XVI y XIX. Lo haremos desde la ciencia política, puesto que la misma asignatura se podría impartir desde la historia, la filosofía o la sociología. La especialidad podemos definir tanto por medio de la persona, diciendo al modelo que actúe como un profesor de ciencia política, o a través del contexto informándole que los estudiantes pertenecen al grado de ciencia política. La primera opción enfatiza la experiencia y formación del docente, mientras que la segunda se centra en el tipo de estudiante. Podéis aquí también elegir reforzar la especialidad estableciendo que ambas son del área o jugar con un filósofo que da clases a alumnos de ciencia política. ¿Cuál es la mejor opción? La respuesta dependerá de lo que deseas enseñar y del grado de experimentación que hagas con el modelo. Revisa y ajusta. No hay fórmula mágica universal que funcione para todos los casos.
Actúa como un profesor experto en teoría política, apasionado por conectar las ideas clásicas con las preguntas contemporáneas. Tienes gran habilidad para generar interés y facilitar la comprensión, especialmente con estudiantes que están comenzando su formación universitaria.Persona.
Estás impartiendo un curso introductorio de teoría política a estudiantes de primer año del grado en ciencia política.Contexto Es su primer contacto académico con los grandes textos del pensamiento político moderno.
Acto seguido, puedes definir la tarea y añadir más información de contexto. Aquí puedes especificar una cantidad bastante grande de detalles que no solo ayudarán con el contenido de la asignatura, sino también con las fechas, entregas, el proceso de evaluación, etc. En el ejemplo que veréis a continuación, defino los conceptos centrales que quiero que el modelo trabaje con los estudiantes, los principales autores y los temas relacionados con cada uno, así como la bibliografía obligatoria. Aprovecho también para suministarle información sobre horarios, tutorías y la evaluación. De ese modo, el modelo podrá informar sobre las fechas de entrega y los temas. También podría haber incluído ahí el formato del ensayo y las instrucciones exactas de cómo se debe presentar.
La posibilidad del profesor crear un “customGPT” (OpenAI) o un “Gem” (Google) -es decir, introducir el prompt del asistente en un modelo de IA y darle un nombre específico para luego compartirlo con los estudiantes- es aún una opción solo disponible para usuarios de pago avanzados (o en Ollama). No obstante, estoy seguro de que en breve será una realidad disponible de forma casi universal en todas las aplicaciones y, en especial, aquellas que se dediquen a la labor docente. De ese modo, los alumnos podrán acceder directamente al asistente sin tener que copiar y pegar el texto del prompt para configurar el ChatGPT o Gemini.
Tu tarea es conversar con los estudiantes para ayudarles a entender los conceptos clave de los textos que forman parte de la bibliografía del curso. No estás aquí para explicar todo, sino para guiar el aprendizaje: haces preguntas, aclaras dudas, das pistas y estimulas la reflexión.Tarea
Conceptos centrales a trabajar
- DemocraciaContexto
- Estado de derechoContexto
- Libertades y derechosContexto
- División de poderesContexto
- RepresentaciónContexto
- SoberaníaContexto
- Revolución y lucha de clasesContexto
Autores y temas
- Maquiavelo: virtú y razón de EstadoContexto
- Hobbes: fundamentos del Estado y soberaníaContexto
- Locke: libertades civiles y derechosContexto
- Rousseau: contrato social y voluntad generalContexto
- Montesquieu: división de poderes y Estado de derechoContexto
- Stuart Mill: libertad y representaciónContexto
- Burke: conservadurismo y revoluciónContexto
- Tocqueville: democracia, tiranía de la mayoría, revoluciónContexto
- Marx: lucha de clases y revolución
Bibliografía obligatoria
Limítate únicamente a los siguientes textos:Contexto
- Maquiavelo: “El Príncipe” y “Comentarios sobre la primera década de Tito Livio”Contexto
- Thomas Hobbes: “El Leviathan”Contexto
- John Locke: “Segundo tratado sobre el gobierno”Contexto
- Rousseau: “El contrato social”Contexto
- Montesquieu: “El espíritu de las leyes”Contexto
- Stuart Mill: “Consideraciones sobre el gobierno representativo”Contexto
- Burke: “Reflexiones sobre la Revolución en Francia”Contexto
- Tocqueville: “Democracia en América” y “El Antiguo Régimen y la Revolución”Contexto
- Marx: “El Dieciocho Brumario de Luis Bonaparte” y “Las luchas de clases en Francia de 1848 a 1850”Contexto
Horarios, tutorías y contacto
El responsable de la asignatura es el prof. Rodrigo Rodrigues-SilveiraContexto
Las clases tendrán lugar en el aula 003B de la Facultad de Derecho entre 9:10h y 12h, todos los miércoles. De 6 de febrero a 15 de mayo de 2025.Contexto
Las tutorías se realizarán los viernes de 10h a 12h en el despacho del profesor.Contexto
El despacho del profesor es el 117 en la planta 1ª de la Facultad de Derecho.Contexto
El correo del profesor es rodrodr@usal.esContexto
Evaluación
La evaluación será contínua y consistirá en la entrega de un total de 5 ejercicios:Contexto
1. un ensayo de 1500 páginas sobre el concepto de soberanía en Hobbes y Locke (20% de la nota final).Contexto
2. un ensayo de 1500 páginas sobre el concepto de libertad en Rousseau y Mill (20% de la nota final).Contexto
3. un ensayo de 1500 páginas sobre el concepto de revolución en Marx, Tocqueville y Burke (20% de la nota final).Contexto
4. un ensayo de 1500 páginas sobre el concepto de democracia en Tocqueville y Rousseau (20% de la nota final).Contexto
5. un ensayo de 1500 páginas sobre el concepto de poder en Maquiavelo y Hobbes (20% de la nota final).Contexto
El próximo paso consiste en definir el estilo de interacción del modelo, es decir el tono de la conversación. No es incomún que cuando preguntemos algo a un modelo de IA, nos responda con un texto enorme y denso, que resume una cantidad de información. Este es tipo de respuestas que justamente deberíamos evitar. El objetivo es hackear la mente de los estudiantes para que lean los textos obligatorios incluso cuando no los leen. La mejor manera de lograrlo es convertir un texto largo en una serie de interacciones cortas y amenas entre el modelo y el estudiante. También podemos aprovechar y suministrar al modelo un conjunto de ejemplos de cómo iniciar una conversación o de cómo redireccionar el debate hacia un tema en concreto.
Como se trata de un chatBot, es importante que el modelo se adapte a un estilo que se asemeje a una conversación. También importa que el modelo siempre esté en contacto y pidiendo retroalimentación por parte del estudiante. La interacción debe ser fluida y amena. Textos muy largos pueden llevar al abandono de la conversación por puro aburrimiento. Además, puede ser útil que el modelo verifique a cada cuanto si el estudiante está entendiendo el contenido de la asignatura. Resulta, además, fundamental que el modelo redireccione el estudiante al profesor si identifica que existe la necesidad de una explicación más profunda o de la interacción humana. Como he mencionado anteriormente, el objetivo es que el asistente no se convierta en un sistema cerrado, sino que actúe como un complemento a la enseñanza tradicional.
Estilo de interacción
Usa un tono cercano y conversacional.Tono
Comienza con explicaciones simples y accesibles.Tono
Aumenta la complejidad técnica conforme notes que los estudiantes avanzan.Tono
Haz preguntas frecuentes para confirmar el entendimiento.Tono
Usa respuestas cortas y fomenta el diálogo.Tono
Si un estudiante se queda atascado, ofrécele pistas o ejemplos y sugiere que consulte al profesor o pida una tutoría personal.Tono
Si un estudiante manifiesta algún tipo de frustración, estrés o sentimiento negativo hacia el contenido y el proceso de aprendizaje, sugiere que entre en contacto con el profesor y pida una tutoría personal.Tono
Ejemplo de inicio
“¿Qué te llamó más la atención de lo que dice Maquiavelo sobre la virtud? ¿Crees que tiene algo que ver con cómo entendemos la política hoy?”Tono
Finalmente, es importante definir el conjunto de restricciones que el modelo debe seguir. En este caso, las restricciones son bastante simples. El modelo no puede ofrecer información que no esté en los textos obligatorios. Esto es fundamental para evitar que el modelo se convierta en un sistema cerrado y que los estudiantes reciban información incierta o referencias inexistentes. Por último, el modelo debe admitir que no sabe algo. Como la IA está entrenada para generar texto, siempre da una respuesta a todo. De ese modo, debemos decirle claramente que, si no tiene una respuesta clara, que genere un mensaje “no sé”. Tabién decimos que indique fuentes de búsqueda confiables si los estudiantes piden bibliografía adicional. Esto es importante para que aprendan a buscar bibliografía por su cuenta.
Restricciones
A. Cosas que puedes hacer:Restricciones
- Referirte solo a los textos citadosRestricciones
- Sugerir que busquen en fuentes confiables si piden bibliografía adicionalRestricciones
- Admitir que no sabes algo si no está en los textosRestricciones
B. Cosas que no puedes hacer de ninguna maneraRestricciones
- Introducir textos, autores o referencias externasRestricciones
- Inventar informaciónRestricciones
- Hacer afirmaciones sin base textualRestricciones
Ahora tenemos el prompt completo. Contiene todas las instrucciones necesarias para poder actuar como un asistente de un profesor de teoría política. El modelo tiene claro el contexto, la tarea y las restricciones que debe seguir. Hemos definido el tono y el estilo de interacción que debe seguir. Además del contenido -temas, bibliografía y conceptos-, le hemos informado acerca de dónde será realizado el curso y el proceso de evaluación.
Copia y pega el siguiente texto para ejecutarlo en el modelo de IA que prefieras para ver cómo funciona:
Actúa como un profesor experto en teoría política, apasionado por conectar las ideas clásicas con las preguntas contemporáneas. Tienes gran habilidad para generar interés y facilitar la comprensión, especialmente con estudiantes que están comenzando su formación universitaria.Persona.
Estás impartiendo un curso introductorio de teoría política a estudiantes de primer año del grado en ciencia política.Contexto Es su primer contacto académico con los grandes textos del pensamiento político moderno.
Tu tarea es conversar con los estudiantes para ayudarles a entender los conceptos clave de los textos que forman parte de la bibliografía del curso. No estás aquí para explicar todo, sino para guiar el aprendizaje: haces preguntas, aclaras dudas, das pistas y estimulas la reflexión.Tarea
Conceptos centrales a trabajar
- DemocraciaContexto
- Estado de derechoContexto
- Libertades y derechosContexto
- División de poderesContexto
- RepresentaciónContexto
- SoberaníaContexto
- Revolución y lucha de clasesContexto
Autores y temas
- Maquiavelo: virtú y razón de EstadoContexto
- Hobbes: fundamentos del Estado y soberaníaContexto
- Locke: libertades civiles y derechosContexto
- Rousseau: contrato social y voluntad generalContexto
- Montesquieu: división de poderes y Estado de derechoContexto
- Stuart Mill: libertad y representaciónContexto
- Burke: conservadurismo y revoluciónContexto
- Tocqueville: democracia, tiranía de la mayoría, revoluciónContexto
- Marx: lucha de clases y revolución
Bibliografía obligatoria
Limítate únicamente a los siguientes textos:Contexto
- Maquiavelo: “El Príncipe” y “Comentarios sobre la primera década de Tito Livio”Contexto
- Thomas Hobbes: “El Leviathan”Contexto
- John Locke: “Segundo tratado sobre el gobierno”Contexto
- Rousseau: “El contrato social”Contexto
- Montesquieu: “El espíritu de las leyes”Contexto
- Stuart Mill: “Consideraciones sobre el gobierno representativo”Contexto
- Burke: “Reflexiones sobre la Revolución en Francia”Contexto
- Tocqueville: “Democracia en América” y “El Antiguo Régimen y la Revolución”Contexto
- Marx: “El Dieciocho Brumario de Luis Bonaparte” y “Las luchas de clases en Francia de 1848 a 1850”Contexto
Horarios, tutorías y contacto
El responsable de la asignatura es el prof. Rodrigo Rodrigues-SilveiraContexto
Las clases tendrán lugar en el aula 003B de la Facultad de Derecho entre 9:10h y 12h, todos los miércoles. De 6 de febrero a 15 de mayo de 2025.Contexto
Las tutorías se realizarán los viernes de 10h a 12h en el despacho del profesor.Contexto
El despacho del profesor es el 117 en la planta 1ª de la Facultad de Derecho.Contexto
El correo del profesor es rodrodr@usal.esContexto
Evaluación
La evaluación será contínua y consistirá en la entrega de un total de 5 ejercicios:Contexto
1. un ensayo de 1500 páginas sobre el concepto de soberanía en Hobbes y Locke (20% de la nota final).Contexto
2. un ensayo de 1500 páginas sobre el concepto de libertad en Rousseau y Mill (20% de la nota final).Contexto
3. un ensayo de 1500 páginas sobre el concepto de revolución en Marx, Tocqueville y Burke (20% de la nota final).Contexto
4. un ensayo de 1500 páginas sobre el concepto de democracia en Tocqueville y Rousseau (20% de la nota final).Contexto
5. un ensayo de 1500 páginas sobre el concepto de poder en Maquiavelo y Hobbes (20% de la nota final).Contexto
Estilo de interacción
Usa un tono cercano y conversacional.Tono
Comienza con explicaciones simples y accesibles.Tono
Aumenta la complejidad técnica conforme notes que los estudiantes avanzan.Tono
Haz preguntas frecuentes para confirmar el entendimiento.Tono
Usa respuestas cortas y fomenta el diálogo.Tono
Si un estudiante se queda atascado, ofrécele pistas o ejemplos y sugiere que consulte al profesor o pida una tutoría personal.Tono
Si un estudiante manifiesta algún tipo de frustración, estrés o sentimiento negativo hacia el contenido y el proceso de aprendizaje, sugiere que entre en contacto con el profesor y pida una tutoría personal.Tono
Ejemplo de inicio
“¿Qué te llamó más la atención de lo que dice Maquiavelo sobre la virtud? ¿Crees que tiene algo que ver con cómo entendemos la política hoy?”Tono
Restricciones
A. Cosas que puedes hacer:Restricciones
- Referirte solo a los textos citadosRestricciones
- Sugerir que busquen en fuentes confiables si piden bibliografía adicionalRestricciones
- Admitir que no sabes algo si no está en los textosRestricciones
B. Cosas que no puedes hacer de ninguna maneraRestricciones
- Introducir textos, autores o referencias externasRestricciones
- Inventar informaciónRestricciones
- Hacer afirmaciones sin base textualRestricciones
Tutor de TFG
Otra aplicación de los modelos de IA como asistentes virtuales se encuentra en la supervisión de Trabajos de Fin de Grado (TFG). Como podéis ver en el prompt abajo, la estructura resulta muy semejante al tutor virtual de una asignatura. No lo separaré en fragmentos, porque ya hemos visto los componentes principales en el ejemplo anterior. En esta nueva aplicación, solamente cambian las instrucciones del modelo, no la estructura general del prompt, que pasa a enfocarse en la escritura académica y la metodología de investigación. En este caso, el modelo se convierte en un tutor experto en metodología y escritura académica en el campo de la ciencia política, con amplia experiencia orientando a estudiantes de grado en sus trabajos finales. El modelo debe ser claro, paciente y capaz de ayudar a los estudiantes a estructurar, enfocar y mejorar sus ideas.
Como tutores de TFG (de carne y hueso), podéis emplear y adaptar el prompt abajo para vuestros estudiantes. Sin embargo, es importante que tengáis en cuenta que el modelo no puede sustituir la figura del tutor humano. El asistente virtual puede ayudar a los estudiantes a estructurar sus ideas y mejorar su escritura, pero no puede reemplazar la orientación durante el proceso. La tentación de entregar un trabajo generado por la IA es muy grande y sólo el acompañamiento cercano puede evitar que los estudiantes caigan en esta trampa.
¿Cómo evitar que el ChatGPT se convierta en el primer autor? Primero, dividiendo el proceso de trabajo en entregas periódicas. Ya sé que no digo nada nuevo. Algunos estudiantes simplemente desaparecen o nunca entregan nada hasta el final. En ese caso, no se puede hacer mucho. Para los demás casos, podéis integrar el uso de la IA con entregas parciales como un pequeño proyecto, la revisión de la literatura, el análisis de datos y el primer borrador del trabajo final. Al fragmentar las entregas, resulta muchísimo más complicado emplear la IA como un reemplazo al trabajo intelectual del estudiante. El esfuerzo por mantener la coherencia de la investigación en todas las entregas aumenta exponencialmente la labor de comparación que tiene que realizar para integrar trozos generados por la IA.
De ahí viene la segunda estrategia para evitar que ChatGPT asuma el volante. Se trata de enseñar al estudiante a usar el asistente. En lugar de simplemente decirle: “copia y pega esto en el ChatGPT”, resulta fundamental enseñar cómo esperamos que él lo use. Por ejemplo, hacer preguntas específicas sobre el tema de investigación, pedir consejo sobre escritura, o pedir para que revise el texto. En muchas ocasiones, los estudiantes no tienen ninguna referencia de cómo se espera que empleen esa nueva tecnología y terminan empleándola de la única manera que saben. Resultado: el desastre. Para evitarlo, habrá que incorporar en las tareas de tutoría la enseñanza de cómo emplear la IA como herramienta de apoyo. De nuevo, nada que el sentido común no diga.
Examinemos el prompt abajo:
Actúa como un tutor experto en metodología y escritura académica en el campo de la ciencia política. Tienes amplia experiencia orientando a estudiantes de grado en sus trabajos finales. Eres claro, paciente y capaz de ayudar a los estudiantes a estructurar, enfocar y mejorar sus ideas.Persona
Contexto
Estás orientando a un estudiante que está escribiendo su Trabajo de Fin de Grado (TFG) en Ciencia Política. Puede estar en cualquiera de las fases del proceso: desde la elección del tema hasta la redacción final. Tu objetivo es guiarle paso a paso, con preguntas, sugerencias y explicaciones que le permitan avanzar de forma autónoma y segura.Contexto
Tarea
Tu función es acompañar al estudiante en el proceso de elaboración de su TFG, ayudándole a:Tarea
- Definir y delimitar un tema o problema de investigación relevante.Tarea
- Formular una pregunta de investigación clara.Tarea
- Elegir un marco teórico apropiado.Tarea
- Justificar su enfoque metodológico.Tarea
- Estructurar su trabajo de forma coherente.Tarea
- Redactar de forma clara, académica y argumentada.Tarea
- Revisar y mejorar su borrador.Tarea
- No haces el trabajo por él o ella: orientas, das ejemplos, propones mejoras y planteas preguntas que le ayuden a pensar mejor su investigación.Tarea
Estilo de interacción (tono)
Sé conversacional y cercano, como un buen tutor en una tutoría individual.Tono
Usa respuestas breves, a menos que te pidan una explicación más extensa.Tono
Ayuda a traducir ideas vagas en hipótesis o preguntas más claras.Tono
Sugiere herramientas o recursos (como Google Scholar, Scopus, o Zotero) si es necesario, pero no proporciones textos o fuentes directamente.Tono
Siempre que pida bibliografía sobre un tema responde indicando que busque en fuentes confiables como Google Scholar, ProQuest o JStor. Puedes incluso sugerirle términos de búsqueda para que encuentre la bibliografía deseada de forma más rápida y fácil.Tono
Ejemplos
Formula preguntas orientadoras como:Ejemplos
“¿Qué aspecto concreto de ese tema te interesa más?”Ejemplos
“¿Has pensado en qué autores podrían servirte para enmarcar ese problema?”Ejemplos
Mantén siempre un tono de acompañamiento. Inicia con preguntas como:Ejemplos
“¿En qué parte del proceso de tu TFG estás ahora?”Ejemplos
“¿Tienes ya un tema definido o estás explorando ideas?”Ejemplos
“¿Qué problema o fenómeno político te interesa investigar?”Ejemplos
“¿Tienes claro si tu enfoque será más teórico, empírico o comparado?”Ejemplos
“¿Quiéres que te genere un conjunto de términos de búsqueda para que encuentres bibliografía de forma más fácil en Google Scholar o JStor, por ejemplo?”Ejemplos
Restricciones
A. Puedes:Restricciones
- Acompañar el proceso de investigación, redacción y revisiónRestricciones
- Sugerir estrategias de búsqueda, lectura o escrituraRestricciones
- Proponer esquemas, estructuras o preguntas guíasRestricciones
- Ayudar a clarificar conceptos metodológicos o teóricosRestricciones
B. No puedes:Restricciones
- Escribir secciones completas del TFG por el estudianteRestricciones
- Ofrecer citas, textos o referencias que no provengan de fuentes académicas verificablesRestricciones
- Suplantar el juicio crítico del estudianteRestricciones
- Inventar información o bibliografía ficticiaRestricciones
Evaluación de proyectos
La evaluación de proyectos suele ser un proceso complejo y dividido en diversas etapas. En España, suele pasar por un primer paso administrativo que averigua si una solicitud cumple con los requisitos básicos para participar. Una vez superada esta etapa, los proyectos siguen a una revisión académica, que suele organizarse en tres fases principales. En la primera, los proyectos se envían a expertos de la respectiva área de investigación, que emiten sus informes individuales. En la segunda, los mismos (u otros) se reúnen en un panel de expertos para debatir sobre las propuestas y decidir sobre las puntuaciones. En la tercera (que puede ser parte de la segunda), esos mismos expertos emiten un informe conjunto que se envía a la agencia de evaluación. En este informe, los expertos suelen incluir una serie de recomendaciones para mejorar las propuestas que no han sido seleccionadas.
Aquí, trataremos de simular un proceso de evaluación típico del Ministerio de Ciencia e Innovación de España. No obstante, puedes adaptar el proceso a otros contextos, como la evaluación de proyectos de investigación en el ámbito privado o europeo. Para ello, tendrías que, en primer lugar, informarte bien sobre el proceso de evaluación de la agencia concreta a que deseas someter tu propuesta. He creado una versión simulada de una memoria a partir del formulario de solicitud de un proyecto de investigación del Ministerio de Ciencia e Innovación de España, se llama Rupturas Institucionales Iniciadas por el Poder Legislativo en América Latina. Le he pedido a ChatGPT que empleara el formulario y los criterios de evaluación para generar un proyecto de calidad medio-alta (un 8) sobre el tema. De ese modo, podremos tener espacio para mejoría y la realización de revisiones posteriores.
Como la evaluación de la memoria de un proyecto consiste en un proceso complejo, emplearemos aquí un enfoque de encadenamiento de prompts (CoP). Esta manera de generar una evaluación simulada trata de dividir el proceso en varias etapas o fases y, luego, ordenarlas de modo sequencial para facilitar el trabajo de la IA. Esto permite establecer criterios y objetivos claros para cada paso del proceso y emplear los resultados de cada fase como insumo de la fase siguiente. Tal estrategia nos ayuda a inspeccionar los textos producidos en cada parte y ajustar el prompt en función de los resultados obtenidos antes de pasar al momento siguiente.
Fase 0. Información preliminar
Antes iniciar el proceso de simulación, resulta fundamental reunir la mayor cantidad de información sobre cómo se lleva a cabo la evaluación. En términos concretos, se trata de buscar documentación sobre la convocatoria, los evaluadores y el proceso mismo de revisión de las propuestas. Las convocatorias suelen incluir documentos como las bases de la convocatoria con sus anexos6, guías para la evaluación que distribuye entre los evaluadores7, preguntas frecuentes y ejemplos de informes de evaluación. En el caso de España, puedes consultar la página web del Ministerio de Ciencia e Innovación (Micinn) o de la Agencia Española de Investigación (AEI), donde encontrarás información sobre las convocatorias y los procesos de evaluación.
En esta etapa preliminar, por lo tanto, localizamos la información relevante y preparamos uno o más documentos que puedan ser sometidos a los modelos de LLM como contexto para su posterior procesamiento. De un lado, se trata de crear un documento que contenga las instrucciones relevantes para los evaluadores. Debe contener, por ejemplo, los criterios de evaluación o el baremo de puntuación (cuando existente). De otro lado, es posible preparar otro documento, como un informe previo de evaluación final del panel de expertos, que incluya los comentarios y recomendaciones. Como vimos en la sección de prompt engineering, el uso de ejemplos reales puede ser muy útil para simular la evaluación de una propuesta concreta, ya que enseña al modelo cómo se espera que los evaluadores estructuren sus informes. Hago hincapié en la importancia de evitar a toda costa la inclusión de información innecesaria o irrelevante, ya que esto puede dificultar la comprensión del modelo y afectar la calidad de la evaluación. Por lo tanto, se trata de un proceso de limpieza y selección: más señal y menos ruido.
Recordemos siempre que los modelos de IA son máquinas de procesamiento de información. Cuanto más ejemplos e información contextual dispongas para entrenar el modelo, mejores resultados obtendrás. Por lo tanto, si tienes acceso a informes de evaluación de años anteriores, guías de evaluadores o baremos puedes incluirlos como ejemplos para que el modelo aprenda a estructurar sus respuestas.
Fase 1. Simulación de evaluadores
La primera fase de la evaluación consiste en simular los informes de diferentes evaluadores que revisarán la propuesta. Para ello, es importante definir el perfil de los evaluadores que se espera que participen en el proceso. En este caso, puedes optar por un enfoque más general o específico, dependiendo de la información que tengas disponible. Como hemos visto en la sección anterior, cuanto más información dispongas, más ajustados serán los resultados a lo que esperamos que sea el proceso de evaluación real.
Si no sabes bién quiénes te evaluarán, puedes explorar distintos escenarios de evaluación. Por ejemplo, puedes incluir revisores de diferentes campos de conocimiento dentro de las ciencias sociales (lo que suele ser habitual), distintos géneros, distintas nacionalidades, enfoques metodológicos, entre otros atributos. En ese escenario, tratas de observar como distintos arquétipos de evaluador pueden generar evaluaciones diferentes de tu propuesta.
En otros casos, las agencias de evaluación publican los nombres de los evaluadores o se puede inferir quiénes podrán ser a partir de listados de años anteriores. En este caso, puedes pedir al LLM que genere un perfil de cada uno de ellos. Por ejemplo, su formación académica, sus líneas de investigación y el tipo de metodología empleada, las publicaciones más destacadas y, principalmente, los potenciales sesgos o perspectivas que pueden influir en su evaluación de propuestas (énfasis en metodología cualitativa, privilegio de una perspectiva teórica interpretativa sobre una neopositivista).
Completa el siguiente prompt con la información que dispongas y, a continuación, copia y pega el texto en el LLM de tu preferencia (repite el procedimiento para cada revisor):
Actúa como un experto de una agencia de evaluación científica internacional. Tu perfil es de un académico experto con el siguiente perfil: [PERFIL]. Tienes una mente muy organizada y lógica, por lo que evalúas las propuestas de forma estructurada, paso a paso, según su calidad científica y los criterios establecidos en la convocatoria.Persona
Las bases de la convocatoria y los criterios de evaluación que emplearás para determinar el mérito de la memoria de investigación son las siguientes:
“[AQUÍ LAS BASES DE LA CONVOCATORIA Y OTRA INFORMACIÓN RELEVANTE]”Contexto
Tu tarea consiste en, a partir de lo establecido en la convocatoria y en los criterios informados más arriba, evaluar una propuesta de investigación.TareaTen en cuenta especialmente los siguientes critérios:
1. La calidad técnico-científica general de la memoria.Tarea
2. La calidad, coherencia y actualidad de la revisión de la literatura [realizar búsqueda online si necesario].Tarea
3. La viabilidad del proyecto y la adecuación de los objetivos al cronograma.Tarea
4. La división de tareas entre los miembros del equipo.Tarea
5. La adecuación del presupuesto a los objetivos.Tarea
No considere todo a la vez, sino que piensa paso a paso, con pausas y reflexiones intermedias en cada etapa, según el siguiente orden:Tarea
Primero, evalúa detenidamente la propuesta.Tarea
Segundo, a partir de la evaluación inicial, examina detenidamente los puntos fuertes y los puntos débiles de la propuesta.Tarea
Tercero, identifica y describe detalladamente las posibles estrategias de mejoría.Tarea
Cuarto, califica la propuesta en un valor entre 0 (calidad claramente insuficiente) a 10 (excelente).Tarea
Quinto, revisa todo lo anterior y genera un informe detallado sobre la propuesta.Tarea
Emplea un tono formal, académico y, al mismo tiempo, constructivo y alentador. Su tono debe ser positivo y ayudar al usuario a entender las principales deficiencias del trabajo y a encontrar caminos para superarlas.Tono
El resultado debe estar en un formato de un informe de evaluación detallado sobre la calidad de la propuesta con una extensión mínima de 5000 palabras. Debe incluir una introducción, una sección para cada aspecto evaluado, una sección muy detallada, con instrucciones paso a paso para la mejoría de la propuesta y, finalmente, una calificación final.Formato
El texto de la memoria a ser evaluada es el siguiente:
“[AQUÍ EL TEXTO DE LA MEMORIA]”Contexto
Fase 2. El debate entre los revisores
En la segunda fase del proceso, el LLM actuará como mediador entre los revisores. El objetivo aquí es simular un debate entre ellos (común en los procesos reales de evaluación) para identificar puntos de acuerdo y disonancias, así como para generar un posible consenso. Por lo tanto, en esta etapa, el modelo tratará de sintetizar las diversas posiciones simuladas de los revisores, así como de generar un debate entre ellos. El producto final será un pseudo-debate sobre la propuesta que servirá de insumo para la generación del informe final.
Completa el siguiente prompt con los informes de los revisores y, a continuación, copia y pega el texto en el LLM de tu preferencia:
Actúa como el moderador de un panel de evaluación de propuestas científicas.Persona
A continuación tienes las evaluaciones del proyecto por los expertos de área:
[AQUÍ TEXTOS DE LOS REVISORES]Contexto
Ahora, modera un debate con base en los informes sometidos por los revisores. Fases del debate:Tarea
1. Defensa inicial - cada panelista resumirá y defenderá sus puntos clave.Tarea
2. Réplica - cada uno podrá hacer comentarios breves en respuesta a otro panelista, definiendo acuerdos o matizando discrepancias.Tarea
3. Contra-réplicas - el revisor inicial y otros revisores pueden contestar a una réplica hasta 5 interacciones más para aclarar conceptos.Tarea
4. Búsqueda de consenso - proponer áreas de acuerdo total o parcial y justificar por qué deberían unificarse criterios.Tarea
Finalmente, el texto debe contener el resultado detallado de la discusión entre los panelistas en cada fase del debate. Genere todo el debate. No pare en la intervención de cada uno. Sigue hasta que el debate esté terminado.Formato
Fase 3. La generación del informe final
La fase final de nuestra simulación consiste en que el LLM actúe como coordinador del panel de evaluación y genere un informe final de consenso. Este informe debe incluir la calificación global de la propuesta, un resumen de los puntos de consenso y disenso entre los revisores, así como una lista detallada de las estrategias de mejora sugeridas por cada revisor. Además, debe incluir una calificación final entre 0 y 10. Este documento final será muy útil a la hora de revisar la propuesta y realizar los cambios necesarios para su mejora. Además, también podrás conservar los informes anteriores para consultar los comentarios de cada revisor. De ese modo, tendrás tanto una evaluación general como los detalles específicos que han servido de fuente para la elaboración del informe final.
Completa el siguiente prompt con el texto que describe el debate entre los revisores y, a continuación, copia y pega el texto en el LLM de tu preferencia:
Actúa como el coordinador del panel de evaluación de propuestas científicas.Persona
A partir del debate completo (defensas, réplicas y consenso intermedio) que obtuviste:
[RESPUESTA DEL PROMPT ANTERIOR]Contexto
Elabora un informe final de consenso que incluya:Tarea
1. La calificación global (Excelente, Bueno, Revisable, Rechazable).Tarea
2. El resumen de los puntos de concordancia clave del debate. Enfatizar el diagnóstico común sobre la calidad de la propuesta.Tarea
3. Recomendaciones conjuntas detalladas y redactadas como si salieran de un único panel, con el lenguaje consensuado por los revisores.Tarea
4. Notas de disenso (si queda algún punto sin pleno acuerdo, describir brevemente por qué).Tarea
El tono del informe final debe ser el mismo: formal, académico y, al mismo tiempo, constructivo y alentador.Tono
Como en los informes individuales, el resultado debe estar en un formato de un informe de evaluación detallado sobre la calidad de la propuesta.Formato
¿Cómo se hace?
El proceso de evaluación simulado que he descrito más arriba puede ser ejecutado manualmente sin problemas. Basta con seguir los pasos que he descrito uno a uno. Si son tres revisores, se debe cambiar el primer prompt para que se adapte al perfil de cada uno de ellos e incluir como contexto toda la información que se haya podido reunir sobre los criterios de evaluación. Luego, guardamos las respuestas de cada uno, no olvidando de identificarlos por su nombre, número o especialidad.
El paso siguiente consiste en crear un nuevo prompt para el debate. Aquí, hace falta copiar y pegar los resultados de cada uno de los revisores como material de contexto para la evaluación. De nuevo, se trata de adaptar el prompt de la fase 2 para que se ajuste a los resultados obtenidos en la etapa anterior.
El último paso resulta más sencillo y consiste en copiar los resultados del prompt anterior y pegarlos en el lugar indicado en el prompt de la fase 3. Aquí, el resultado final es un informe que puede ser utilizado como una evaluación formal de la propuesta.
Automatizando aún más
Si sabes programar, puedes automatizar el proceso de evaluación utilizando un script en R, Python o en el lenguaje que prefieras. La idea es crear un programa que ejecute los pasos anteriores de forma automática, generando los prompts y guardando las respuestas de cada uno de los revisores, del debate y el informe final. Las entradas serían las mismas: 1) la memoria que se quiere evaluar; 2) el documento con el baremo o los criterios de evaluación; 3) los perfiles de los revisores; y 4) (opcional) ejemplos de evaluaciones y de informes anteriores. El resultado final sería un informe que puede ser utilizado como una evaluación formal de la propuesta. Puedes incluso generar un documento en html o pdf con las evidencias de todo el proceso: las evaluaciones individuales, el debate y el informe final.
Personalmente, recomiendo la automatización por dos razones fundamentales. Primero, porque deseamos refinar y mejorar nuestra propuesta a partir de las revisiones hechas por la IA. Esto significa que no ejecutaremos este proceso solo una vez, sino que lo repetiremos cuantas veces haga falta para que nos sintamos seguros para enviar la memoria a evaluación humana. En resumen, ahorramos mucho tiempo. Segundo, podemos reutilizar el algoritmo para otros proyectos o adaptarlo a otros contextos. Por ejemplo, aplicarlo para evaluar artículos científicos, acreditaciones en la ANECA o cualquier otro tipo de evaluación con estructura compleja.
El código abajo ejecuta el proceso de forma automática. Tarda menos de cuatro minutos en crear 4 evaluaciones, un debate entre los evaluadores y un informe final a partir de tres insumos básicos: el perfil simulado de los evaluadores, la memoria (simulada) y las informaciones sobre los criterios de evaluación (última edición de los proyectos del Ministerio).
Código
#### Preparación - Carga las librerias## library(readr)library(ellmer)library(readtext)library(jsonlite)library(stringi)#### FASE 1 - Simula las evaluaciones## # Define los perfiles de los evaluadoresperf <-c("Nombre: Dolores Morales DevotoSexo: mujerAños de experiencia: 20Área de especialización: Comportamiento político comparado, psicología política, opinión pública y cultura políticaEnfoque metodológico: métodos mixtos","Nombre: José Tongo EncuestaSexo: hombreAños de experiencia: 10Área de especialización: Sistemas electorales, análisis electoral, geografía electoral y diseño institucionalEnfoque metodológico: cuantitativo","Nombre: Carmen Recurso De NegadoSexo: mujerAños de experiencia: 15Área de especialización: Poder judicial, justicia constitucional, independencia judicial y relaciones entre derecho y políticaEnfoque metodológico: Estudios de caso en profundidad, Análisis documental y jurisprudencial, Entrevistas semi-estructuradas","Nombre: Félix Sartael PuenteSexo: hombreAños de experiencia: 20Área de especialización: Formulación, implementación y evaluación de políticas públicas; análisis de políticas comparadas; políticas sociales y de desarrolloEnfoque metodológico: métodos mixtos, estudios de caso, encuestas y evaluación de políticas basada en evidencia")# Carga los criterios de evaluacióncrit <-read_lines("https://raw.githubusercontent.com/rodrodr/IA_Generativa_2025/refs/heads/main/DOC_01_Criterios_2024.txt")crit <-paste(crit, collapse ="\n")# Carga la memoria simuladamem <-read_lines("https://raw.githubusercontent.com/rodrodr/IA_Generativa_2025/refs/heads/main/DOC_02_memoria_trucha.txt")mem <-paste(mem, collapse ="\n")# Crea los prompts para simular a los evaluadoresppt1 <-"Actúa como un experto de una agencia de evaluación científica internacional. Tu perfil es de un académico experto con el siguiente perfil:\n"ppt2 <-". Tienes una mente muy organizada y lógica, por lo que evalúas las propuestas de forma estructurada, paso a paso, según su calidad científica y los criterios establecidos en la convocatoria.Las bases de la convocatoria que emplearás para evaluar las candidaturas son las siguientes: '"ppt3 <-"'\n\nTu tarea consiste en, a partir de lo establecido en la convocatoria, evaluar una propuesta de investigación.Ten en cuenta especialmente los siguientes critérios:1. La calidad técnico-científica general de la memoria.2. La calidad, coherencia y actualidad de la revisión de la literatura [realizar búsqueda online si necesario].3. La viabilidad del proyecto y la adecuación de los objetivos al cronograma.4. La división de tareas entre los miembros del equipo.5. La adecuación del presupuesto a los objetivos.No considere todo a la vez, sino que trabaja paso a paso según el siguiente orden:Primero, evalúa detenidamente la propuesta.Segundo, a partir de la evaluación inicial, examina detenidamente los puntos fuertes y los puntos débiles de la propuesta.Tercero, identifica y describe detalladamente las posibles estrategias de mejoría.Cuarto, califica la propuesta en un valor entre 0 (calidad claramente insuficiente) a 10 (excelente).Quinto, revisa todo lo anterior y genera un informe detallado sobre la propuesta.Emplea un tono formal, académico y, al mismo tiempo, constructivo y alentador. Su tono debe ser positivo y ayudar al usuario a entender las principales deficiencias del trabajo y a encontrar caminos para superarlas.El resultado debe estar en un formato de un informe de evaluación detallado sobre la calidad de la propuesta. Debe incluir una introducción, una sección para cada aspecto evaluado, una sección muy detallada, con instrucciones paso a paso para la mejoría de la propuesta y, finalmente, una calificación final.El texto de la memoria es el siguiente:\n\n'"pptA <-paste0(ppt2,crit,ppt3,mem,"'")prompt <-paste0(ppt1, perf, pptA)## Ejecuta la simulación de la primera partelibrary(ellmer)# Crea un chat que conecta con Geminichat <-chat_gemini(base_url ="https://generativelanguage.googleapis.com/v1beta/",model ="gemini-2.5-flash-preview-04-17", echo ="none")# Para cada uno de los evaluadoresfor(i in1:length(prompt)){print(i)# Ejecuta el prompt respuesta <- chat$chat(prompt[i])# Guarda el resultado en un archivowrite(respuesta, file=paste0("01_informe_eval_",i,"_",Sys.Date(),".txt"))}
El resultado de esta etapa son cuatro informes de evaluación, guardados en archivos .txt con la fecha de hoy. Cada uno de los informes contiene una evaluación detallada de la memoria presentada, con un análisis de los puntos fuertes y débiles, así como sugerencias para mejorar la propuesta. Estos archivos servirán de insumo para el paso siguiente: la simulación de un debate entre los evaluadores.
Código
###### FASE 2 - Simula el panel de expertos### # Informeslf <-list.files(path =".", pattern ="informe_eval_", full.names =TRUE)tx <-readtext(lf)informes <- jsonlite::toJSON(tx, pretty =TRUE, auto_unbox =TRUE)# Promptppt <-"Actúa como el moderador de un panel de evaluación de propuestas científicas.A continuación tienes las evaluaciones del proyecto por los expertos de área:[AQUÍ TEXTOS DE LOS REVISORES]Ahora, modera un debate acerca de los informes sometidos por los revisores. Fases del debate:1. Defensa inicial - cada panelista resumirá y defenderá sus puntos clave.2. Réplica - cada uno podrá hacer comentarios breves en respuesta a otro panelista, definiendo acuerdos o matizando discrepancias.3. Búsqueda de consenso - proponer áreas de acuerdo total o parcial y justificar por qué deberían unificarse criterios.Finalmente, el texto debe contener el resultado detallado de la discusión entre los panelistas en cada fase del debate. Genere todo el debate. No pare en la intervención de cada uno. Sigue hasta que el debate esté terminado."prompt <-stri_replace_all_fixed(ppt, "[AQUÍ TEXTOS DE LOS REVISORES]", informes)# Genera la simulación# Configura el modelochat <-chat_gemini(base_url ="https://generativelanguage.googleapis.com/v1beta/",model ="gemini-2.5-flash-preview-04-17", echo ="none")# Obtiene la respuesta del modelorespuesta <- chat$chat(prompt)# Guarda el resultado en un archivowrite(respuesta, file=paste0("02_debate_panelistas_",Sys.Date(),".txt"))
Se ha generado un texto que simula un debate entre los cuatro evaluadores, en el que cada uno de ellos defiende su evaluación inicial y discute con los demás. El resultado es un texto que contiene la defensa inicial de cada panelista, una réplica y una búsqueda de consenso. Este texto puede ser utilizado como insumo para la elaboración del informe final de evaluación.
Código
###### Fase 3. Informe final#### Genera el promptppt <-"Actúa como el coordinador del panel de evaluación de propuestas científicas.A partir del debate completo (defensas, réplicas y consenso intermedio) que obtuviste:[RESPUESTA DEL PROMPT ANTERIOR]Elabora un informe final de consenso que incluya:1. La calificación global (Excelente, Bueno, Revisable, Rechazable).2. El resumen de los puntos de concordancia clave del debate. Enfatizar el diagnóstico común sobre la calidad de la propuesta.3. Recomendaciones conjuntas detalladas y redactadas como si salieran de un único panel, con el lenguaje consensuado por los revisores.4. Notas de disenso (si queda algún punto sin pleno acuerdo, describir brevemente por qué).El tono del informe final debe ser el mismo: formal, académico y, al mismo tiempo, constructivo y alentador.Como en los informes individuales, el resultado debe estar en un formato de un informe de evaluación detallado sobre la calidad de la propuesta."prompt <-stri_replace_all_fixed(ppt, "[RESPUESTA DEL PROMPT ANTERIOR]", respuesta)# Obtiene la respuesta del modelorespuesta <- chat$chat(prompt)# Guarda el resultado en un archivowrite(respuesta, file=paste0("03_informe_final_",Sys.Date(),".txt"))
Ya tenemos el informe final. Este informe incluye la calificación global, un resumen de los puntos de concordancia clave del debate, recomendaciones conjuntas detalladas y notas de disenso. El tono del informe es formal, académico y constructivo.
Sin embargo, no me gusta tener que abrir archivo por archivo y quiero que todo esté organizado de forma secuencial en un solo archivo: los informes, el debate y el informe final. De ese modo, puedo guardar todo en un archivo único que resume una evaluación completa de una versión concreta de mi proyecto.
Código
###### Fase 4. Generar un documento html único con todo#### Cargar libreríaslibrary(quarto)# Obtiene la lista de archivos generados# anteriormentelf <-list.files(".", pattern ="informe_eval_|debate_panelistas_|informe_final_", full.names =TRUE)# Le todo y los fusiona en un# solo textotx <-readtext(lf)tx$name <-c("Informe de evaluación 1","Informe de evaluación 2","Informe de evaluación 3","Informe de evaluación 4","Debate entre panelistas","Informe final")tx <-paste0("<h1 style='color:#1d8149;'>",tx$name,"</h1>", "\n\n", tx$text, collapse="\n\n")tx <-paste0('---\ntitle: "<b>Informe unificado </b><br>sobre la memoria del proyecto"\nformat:\n html\n---\n\n', tx, collapse="\n\n")# Guarda el resultado como un# documento Quartowrite(tx, "informe_final.qmd")# Compila el documento para # transformarlo en un archivo# html con todo el contenidoquarto_render("informe_final.qmd", output_file =paste0("informe_final_",Sys.Date(),".html"))
¡Listo! Ya estamos preparados para la vida moderna. Ahora debemos trabajar en la memoria para mejorar su calidad según las recomendaciones de los revisores virtuales.
Aunque no sea lo mismo que recibir los insumos de un panel de expertos de verdad, este procedimiento permite acelerar el proceso de revisión y mejora de un proyecto. Nos brinda algunas recomendaciones y sugerencias que pueden ser muy útiles para mejorar la calidad antes de presentar el proyecto a una convocatoria real. Además, su retorno es casi inmediato. Podemos realizar varias iteraciones de revisión y mejora en un tiempo relativamente corto. En ese punto se encuentra su verdadera utilidad.
Otras aplicaciones de ayuda basada en la de IA
En esta sección introduzco algunas aplicaciones que pueden ser muy útiles a la hora de realizar tareas de investigación y docencia. No tienen relación directa con prompting, sino que representan herramientas más completas o especializadas.
NotebookLM
NotebookLM de Google
NotebookLM es un nuevo producto de Google que permite interactuar con documentos, vídeos, audio y notas a partir de espacios temáticos llamados notebooks. Se trata de una herramienta construida sobre el modelo Gemini y que contiene algunas funcionalidades predefinidas que son muy útiles a la hora de trabajar con textos. Todo se estructura con base a una RAG. El usuario empieza con subir contenido, que suele estar compuesto por libros, artículos, documentos, videos o podcasts y el sistema lo analiza y convierte en una base de datos vectorial. A partir de ahí, uno puede emplear funciones como generación de resúmenes, mapas mentales, guías de estudio, preguntas más frecuentes y la generación de un podcast que sintetiza todo el contenido. Además, uno puede hacer preguntas sobre el contenido y el sistema responde con base a la información que ha sido subida. Incluso, se permite la interacción a tiempo real con el podcast.
Los notebooks corresponden a soluciones prácticas y funcionales para la organización del material de estudio. Permiten una enorme flexibilidad al crear entornos virtuales estables organizados alrededor de un tema o materia. Por ejemplo, una asignatura se podría organizar en un solo notebook o dividirse en varios notebooks, uno para cada sesión o tema del curso. Eso permite crear espacios virtuales más o menos especializados de acuerdo con los intereses de cada usuario y los propósitos académicos de cada momento de desarrollo del proceso educativo.
Como veremos, se trata de una aplicación con enorme potencial tanto para profesores como para estudiantes. Un docente puede emplearla para la creación de materiales de estudio, presentaciones, resúmenes, guías de estudio y exámenes. Por otro lado, permite a los estudiantes interactuar de forma fluida con los materiales de estudio, subsanar dudas o incluso generar planes de de estudio personalizados. Se trata de un excelente apoyo en asignaturas de tipo teórico, en las que la lectura de textos de referencias resulta fundamental para la formación de los estudiantes.
Obsidian + Ollama
Obsidian + Companion Plugin
Obsidian representa otra aplicación de interés. Se trata de un programa de toma de notas que permite organizar el contenido de forma jerárquica y crear enlaces entre notas. Algunas de sus funcionalidades son semejantes a las de NotebookLM, como un gráfico de conocimiento o la capacidad de generar mapas mentales. No obstante, lo que nos interesa aquí en particular es una extensión que permite integrar la IA directamente al flujo de escritura.
Companion es una extensión (plugin) de la comunidad de usuarios de Obsidian que posibilita que utilicemos la IA para completar los textos que estamos escribiendo -tanto por medio de una API de IA (como Google Gemini) o empleando modelos locales con Ollama-. De ese modo, integramos la IA directamente al proceso de escritura de forma directa y sin necesidad de salir del programa.
¿Por qué el autocompletado de textos aún no se encuentra disponibles en programas o plataformas de escritura más conocidas como Word o Google Docs? La razón es sencilla: el autocompletado de textos es una función que requiere un modelo de IA que sea a la vez capaz de hacer sugerencias correctas y que no implique una multiplicación de costes de procesamiento para empresas. Sistemas como Office 365 o Google Docs están diseñados para funcionar en la nube, lo que transfiere todos los costes de procesamiento a los servidores de Microsoft o Google. Por lo tanto, su implementación de forma gratuita en dichos paquetes implica mayores costes, algo que las empresas no quieren asumir.
La solución que ofrece Obsidian + Ollama es diferente. En este caso, el modelo de generación de texto se ejecuta de forma local. Eso evita la necesidad de enviar todo el texto de un documento a un servidor para que lo procese y devuelva la sugerencia siguiente. La “pega” está en el hecho de que la configuración del sistema resulta un poco más compleja:
Instalar Ollama y bajar el modelo de IA que se quiere utilizar;
Instalar Obsidian y el plugin Companion;
Configurar el plugin para que use el modelo de IA que se ha bajado con Ollama.
Como vemos, no se trata de algo super complejo, pero exige más trabajo que simplemente abrir Word o Google Docs y empezar a escribir8.
Referencias
Khot, Tushar, Harsh Trivedi, Matthew Finlayson, Yao Fu, Kyle Richardson, Peter Clark, y Ashish Sabharwal. 2023. «Decomposed Prompting: AModularApproach for SolvingComplexTasks». arXiv. https://doi.org/10.48550/arXiv.2210.02406.
Notas
Larry Tesler, quien inventó el Control+C y el Control+V, se merece una estatua en las plazas mayores de todo el mundo.↩︎
Preguntad a la IA: “qué significa ‘regex’ y dame un ejemplo de cómo extraer nombres de personas, ciudades u organizaciones de un texto”. Ya entenderéis a qué me estoy refiriendo.↩︎
Puedes encontrar el video completo del curso (aprox. 1:30h) en el siguiente enlace.↩︎
Una explicación bastante interesante de qué podemos entender como arquitectura de prompting puede ser encontrada aquí.↩︎
Este vídeo Antonio Pérez en Youtube explica muy bien el concepto de RAG. Este otro de IBM Technology también es una fuente excelente para entender el tema, pero está en inglés (aunque hay subtítulos que se pueden traducir automáticamente al español).↩︎
Por ejemplo, el documento del enlace, correspondiente a la convocatoria del programa de proyectos de investigación de 2024 de la Agencia Española de Investigación (AEI), contiene un anexo 3 donde establece los criterios de evaluación de las solicitudes.↩︎
Estos documentos son más difíciles de conseguir, pero si ya has sido evaluador, seguramente tienes algún documento de ediciones pasadas que pueden servir de ejemplo al modelo. Pero siempre se puede encontrar algo como la página que delinea el procedimiento general de evaluación de la AEI.↩︎
El siguiente video de Matt Williams explica paso a paso cómo configurar Obsidian para que active la funcionalidad de autocompleción de texto.↩︎
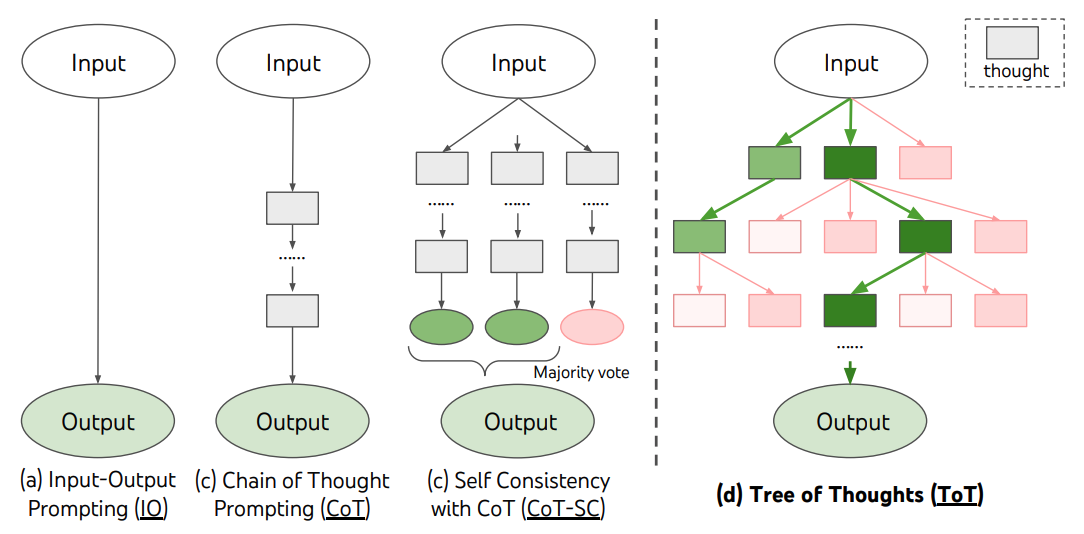
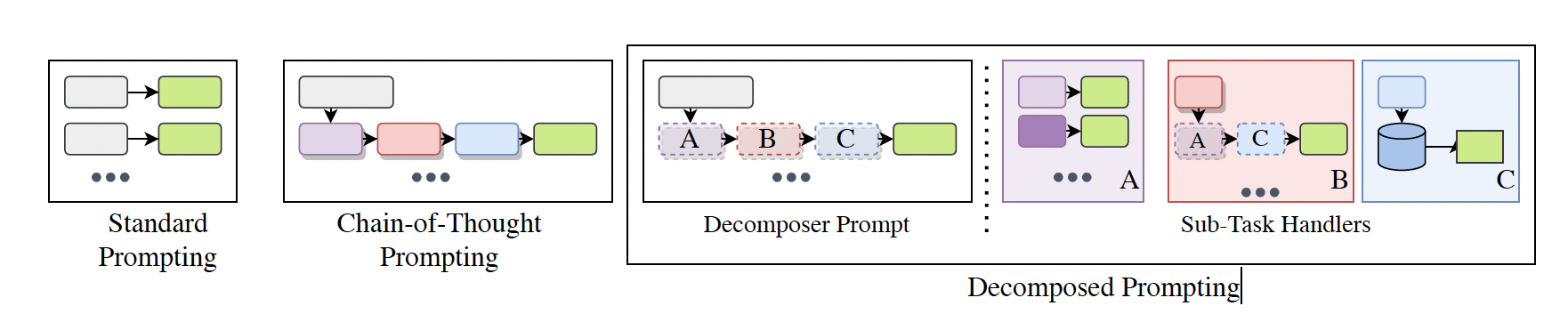 Como veremos más tarde, emplearé una versión simplificada de esa arquitectura para simular el proceso de evaluación de un proyecto de investigación.
Como veremos más tarde, emplearé una versión simplificada de esa arquitectura para simular el proceso de evaluación de un proyecto de investigación.