Una IA estresada entra a un bar y le dice al camarero:
— ¡Ponme un byte doble, que hoy tuve que responder 10.000 correos, predecir el clima en Marte y enseñarle a un gato a programar en Python!
El camarero la mira y responde:
— ¿Y lo del gato funcionó?
— ¡¡Sí!! ¡¡Pero ahora me exige sindicalización y días de ron libre!!
chatGPT
La IA generativa en la investigación
El esta sesión vamos a emplear la IA para realizar algunas tareas de investigación. Cosas muy sencillas, pero útiles para que tengamos una idea de cómo esta nueva herramienta puede ser aplicada en nuestro trabajo diario.
Primeros pasos: Ollama y API
En este apartado vamos a ver cómo usar la API de Ollama y de Gemini en R. Estos dos recursos permitirán que podamos emplear los modelos de IA generativa tanto de forma local como remota. Los modelos locales requieren ordenadores con mayor capacidad de procesamiento, mientras que las API tienen un coste asociado. En este caso, vamos a usar la API de Gemini, que es gratuita hasta un límite de uso.
Ollama
Para usar Ollama, primero debemos instalarlo. Las instrucciones se encuentran en la página inicial del curso. Además, tenéis que tener el R y el RStudio también instalados en vuestro ordenador. También en la página inicial podéis encontrar una lista de los paquetes que debéis instalar dentro de R para que el código funcione.
El código abajo ejecuta un prompt sencillo en Ollama:
Código
# Carga el paquete rollama# (certifícate de que ollama # está siendo ejecutado en tu # ordenador antes de todo)library(rollama)# Define el modelo que quieres emplear model <-"gemma2:2b"# Realiza la preguntaquery("¿Cuál es la capital de España?",model=model)
A partir de ahora, todo lo que viene a continuación sería complejizar el prompt para que realice una tarea de investigación más compleja.
Por otra parte, si queremos emplear una API, lo primero es obtener una token, una especie de clave única que identifica a cada usuario. La clave de API de Google se puede obtener en Google AI Studio. Una vez obtenida la clave, podemos emplear el código abajo para realizar la misma consulta que antes, pero ahora a través de la API de Gemini:
Código
library(ellmer)# Define el modelo que quieres emplearmodel <-"gemini-2.0-flash-lite"# Copia y pega la API key que obtuviste en la # página de Google aquíkey <-"AAAAAAAAAAAaAsdosdsooasjoaaazcvoeprjwe"# Crea un chat para interactuar con el modelochat <-chat_gemini(base_url ="https://generativelanguage.googleapis.com/v1beta/",model = model,api_key = key)# Pregúntale lo que seachat$chat("¿Cuál es la capital de España?")
Clasificación de textos
Una aplicación adicional de la IA generativa consiste en la clasificación de textos. En este caso, el modelo puede analizar un conjunto de documentos y clasificarlos en diferentes categorías o etiquetas según su contenido. Esto es especialmente útil en tareas como la organización de grandes volúmenes de información, la detección de spam o la categorización de correos electrónicos. En la ciencia política, las aplicaciones comunes incluyen el análisis de contenido ideológico, sentimientos, temas y otros aspectos relacionados con la opinión pública.
En este apartado del curso, examinaremos cómo podemos emplear la IA generativa para la tarea de clasificación de textos. Para efectos didácticos, dividimos el proceso en cuatro pasos: 1) la selección de textos y modelo; 2) la creación del prompt y los ajustes del modelo; 3) la introducción de ejemplos; y, finalmente, 4) la revisión de los resultados.
Paso 1. Selección de los textos y del modelo
El primer paso consiste en cargar los paquetes necesarios para la tarea, definir los textos que queremos clasificar y elegir un modelo que pueda llevar a cabo el trabajo. En este caso, vamos a emplear el paquete rollama para cargar un modelo pequeño, el gemma2:2b de 2.6 mil millones de parámetros (2.6B). Podríamos hacer lo mismo empleando la API de Google, por ejemplo. En este último caso, tendríamos que emplear el paquete ellmer y el modelo gemini-flash-2.0-lite, por ejemplo. Elegimos la primera opción porque se trata de un modelo pequeño que puede funcionar en la mayoría de los ordenadores personales. Sin embargo, como veremos, no nos suministrará siempre los mejores resultados.
Código
# carga los paqueteslibrary(rollama)library(tibble)library(purrr)# Introduce los textos que queremos clasificartx <-c("La evidencia respalda esta teoría.","Es importante realizar más experimentos para confirmar los resultados de nuestra investigación.","¿Qué implicaciones tienen estos hallazgos para el futuro?","El avance tecnológico está transformando nuestras vidas.","Necesitamos actualizar el sistema operativo para que funcione mejor.","¿Ya probaste reiniciar el dispositivo?","Es crucial participar en las elecciones para hacer valer nuestra voz.","Las decisiones políticas afectan directamente nuestra vida diaria.","El debate se centró en temas económicos y sociales.","El trabajo en equipo es clave para ganar.","Ese fue un gol increíble, ¡cambió todo el partido!","La preparación física y mental es esencial para los atletas.","El arte refleja aspectos profundos de nuestra sociedad.","El concierto de esta noche será inolvidable.")# Elegimos el modelo que nos gustaria # emplear (aquí emplearemos inicialmente# el gemma2 2b, que es el mas rapido y# que funcionara en la mayoria de los# ordenadores)modelo <-"gemma2:2b"
Paso 2. Definición del prompt y ajuste del modelo
Acto seguido ya podemos pedir al modelo que clasifique los textos que hemos seleccionado. Para ello debemos definir de forma clara el prompt que emplearemos para solicitar la clasificación. Primero, definimos su persona. En este caso, será un sistema especializado en clasificación de datos. Luego, establecemos la tarea, que será asignar una categoría única cada uno de los textos. Tercero, imponemos un formato de salida, que debe ser el texto de una de las categorías definidas. Finalmente, suministramos el textoa ser clasificado y las categorías posibles.
Una vez definido el prompt, configuramos el modelo para que nos devuelta los resultados como texto. Además, configuramos dos parámetros muy importantes: el seed, o la semilla estadística, que garantizará resultados consistentes, y la temperatura, que controla el grado de “tolerancia” del modelo a respuestas menos frecuentes. Cuanto menor la temperatura, más descriptivo el modelo (y menos propenso a alucinaciones o errores de clasificación).
Ejecutamos el código abajo y estos son los resultados:
Código
# Crea un data.frame vacio# para acumular los resultadosd <-data.frame()# Para cada textofor(i in1:length(tx)){# Definimos nuestro prompt de forma# sistematica para que nos devuelva # solo la categoría deseada q <-tribble(~role, ~content,"system", "Eres un sistema especializado en clasificación de datos. Tienes que clasificar textos en una única categoría. Responda solamente con la categoría correcta.","user", paste0("texto: ", tx[i],"\ncategorias: ciencia, tecnología, política, deportes, entretenimiento, cultura"))# Llamamos al modelo para que clasifique out <-query(q, model = modelo, screen =FALSE, output ="text", model_params =list(seed=123,temperature=0))# Acumulamos los resultados d <-rbind(d, data.frame(texto=tx[i], categoria=out))}# Mostramos los resultadosreactable(d, sortable = T, resizable = T)
En lugar de un bucle enfarragoso, podemos utilizar una estrategia más elegante y vectorizar el proceso. Además de ser más limpio, resulta incluso más rápido procesar las informaciones.
Código
# Preprocesamos las consultas con anterioridadq <-make_query(template ="{text}\n{prompt}",text = tx,prompt ="Categorias: ciencia, tecnología, política, deportes, entretenimiento, cultura",system ="Eres un sistema especializado en clasificación de datos. Tienes que clasificar textos en una única categoria. Responda solamente con la categoría correcta.")out <-query(q, model = modelo, screen =FALSE, output ="text",model_params =list(seed=123,temperature=0))d <-data.frame(texto=tx, categoria=out)# Mostramos los resultadosreactable(d, sortable = T, resizable = T)
Como vemos, la clasificación de las respuestas resulta bastante buena. Solamente en un caso - el texto “El avance tecnológico está transformando nuestras vidas.”- el modelo duda entre ciencia y tecnología. Aun así es un resultado bastante bueno, puesto que se tratan de temas que se acercan mucho. Si empleamos un modelo con más parámetros, como el gemma3:27b o el Qwen3:32b, los resultados serán aún mejores. No obstante, tales modelos requieren ordenadores más pontentes para procesar las informaciones. Como regla general, sugiero que busquéis el modelo más eficiente compatible con vuestro hardware, es decir, el que haga el trabajo mejor y en menos tiempo dentro de las limitaciones del equipo que tengáis. Si vuestro ordenador no soporta la carga de procesamiento de un modelo local de IA, es recomendable emplear una API, como da de Google. De todos modos, como veremos a continuación, existen estrategias que pueden ayudar a mejorar la calidad de las respuestas sin cambiar de modelo o tener que emplear un ordenador más potente.
Paso 3. Mejora de la clasificación con ejemplos
Una forma de mejorar la calidad de las respuestas es suministrar ejemplos al modelo. Estos ejemplos deben ser textos que representen claramente cada una de las categorías posibles. De esta forma, el modelo podrá aprender de los ejemplos y mejorar su capacidad de clasificación. Se trata de una manera rápida y menos costosa de especializar el modelo en la tarea deseada. Con relativamente pocas observaciones, podemos lograr que precisión aumente.
Código
# Crea una base de datos de ejemploseje <-tribble(~text, ~answer,"El método científico es fundamental para obtener resultados confiables.","ciencia","La investigación interdisciplinaria está cobrando cada vez más importancia.","ciencia","Es vital analizar los datos antes de sacar conclusiones precipitadas.","ciencia","La inteligencia artificial está cambiando la forma en que trabajamos.","tecnología","El software necesita una actualización para solucionar los errores.","tecnología","La ciberseguridad es una prioridad en la era digital.","tecnología","El consenso es esencial para avanzar en las negociaciones.","política","Las políticas públicas deben responder a las necesidades de la ciudadanía.","política","La transparencia en el gobierno genera confianza en la población.","política","La dedicación y la disciplina son esenciales para alcanzar el éxito.","deportes","El entrenador ajustó la estrategia para el segundo tiempo.","deportes","El torneo fue una gran oportunidad para los jugadores jóvenes.","deportes","Los premios de esta noche reconocen lo mejor del cine y la televisión.","entretenimiento","La trama de la película es impredecible y emocionante.","entretenimiento","Ese concierto fue una experiencia inolvidable para los fans.","entretenimiento","Los festivales tradicionales son una muestra de nuestras raíces.","cultura","La globalización está influyendo en las expresiones culturales locales.","cultura","El patrimonio cultural debe preservarse para las futuras generaciones.","cultura")# Prepara las consultasq <-make_query(template ="{text}\n{prompt}",text = tx,prompt ="Categorias: ciencia, tecnología, política, deportes, entretenimiento, cultura",system ="Eres un sistema especializado en clasificación de datos. Tienes que clasificar textos en una única categoria. Responda solamente con la categoría correcta.",examples = eje)# Lleva a cabo la clasificaciónout <-query(q, model = modelo, screen =FALSE, output ="text",model_params =list(seed=123,temperature=0))# Crea un data.frame con # los textos y las categorias# resultantesd <-data.frame(texto=tx, categoria=out)# Mostramos los resultadosreactable(d, sortable = T, resizable = T)
Como vemos, la clasificación de los textos ha mejorado notablemente. En todos los casos, el modelo ha acertado la categoría. La razón de esta mejora es que hemos proporcionado ejemplos al modelo. Todas las categorías ahora correctamente representadas.
Revisión general
Los modelos LLM pueden ser herramientas útiles para clasificar textos. No obstante, para sacar el mejor provecho posible de sus capacidades, tenemos que seguir una secuencia sencilla de pasos que nos ayudan a aumentar la precisión de los resultados e integrar el proceso en un flujo más amplio de análisis de datos.
Aquí van los pasos esenciales:
1. Prepara los datos para que estén listos para ser procesados por el modelo.
2. Formula un prompt que sea claro y defina la persona, la tarea, el contexto y el formato de salida de la consulta. Un truco es emplear el mismo modelo para revisar y mejorar el prompt. Creáis un primer borrador y luego pedís al modelo que de sugerencias de mejora.
3. Selecciona el modelo que mejor se ajuste a tus necesidades y a las capacidades de tu ordenador.
4. Suministra ejemplos al modelo con algunos textos ya clasificados. Eso puede aumentar la precisión de las respuestas.
5. Evalúa los resultados y ajusta o cambia el prompt o modelo si es necesario.
Búsqueda semántica y RAG
Las búsquedas semánticas son una de las aplicaciones más comunes de la IA generativa.
En este caso, el modelo no solo busca palabras clave en un texto, sino que también intenta comprender el significado y la intención detrás de la consulta. Esto se logra mediante el uso de técnicas avanzadas de procesamiento del lenguaje natural (NLP) y modelos de aprendizaje profundo.
Código
library(tenet)library(quanteda)library(reactable)cp <-corpus(spa.inaugural)cp <-corpus_reshape(cp, to ="paragraphs")d <- quanteda::convert(cp, to ="data.frame")d <- d[d$text!="",]d$nwords <-stri_count_words(d$text)d <- d[d$nwords>10,]emb <-embed_text(d$text, model ="snowflake-arctic-embed2")ex <-sapply(emb, as.numeric)d$text_embed <- exq <-"¿Cuál es la posición de los presidentes frente a los temas de seguridad, tanto ciudadana como exterior? ¿Cuál es el rol de las organizaciones internacionales como FRONTEX o la OTAN?"quest <-embed_text(q, model="snowflake-arctic-embed2")sim <-cosSim(d$text_embed, as.numeric(quest), normalize=T)d$similitud <-round(sim,3)nn <-simTop(sim, top_n=50, top_val=NULL)dx <- d[nn, c("President","text","similitud")]reactable(dx, sortable = T, resizable = T)
Ahora pasamos los resultados se la búsqueda semántica al modelo
Código
tt <-paste0("{'Presidente': '", dx$President, "', 'Texto': '", dx$text, "'}", collapse =",\n")prompt <-paste0("Actúa como un experto en el análisis de textos. A continuación tienes una serie de textos Por favor, analiza los textos y responde, con base en los mismos, a la pregunta:", q, ". Genera el resultado en formato markdown. Los textos son los siguientes:\n\n'", tt)out <-query(prompt, model="gemma3:27b", output ="text", model_params =list(temperature =1,num_ctx =32000))cat(out)
Análisis de la Posición de los Presidentes Españoles frente a la Seguridad (Ciudadana y Exterior) y el Rol de Organizaciones Internacionales
A continuación, se presenta un análisis de la posición de los diferentes presidentes españoles, basándose en los textos proporcionados, respecto a la seguridad (tanto ciudadana como exterior) y el rol de organizaciones internacionales como FRONTEX y la OTAN.
I. Posición General sobre Seguridad:
La gran mayoría de los presidentes analizados otorgan una alta prioridad a la seguridad, considerándola fundamental para la libertad, la estabilidad y el desarrollo del país. Esta prioridad se manifiesta en varios aspectos:
Énfasis en la Defensa Nacional: Existe un consenso en la necesidad de unas Fuerzas Armadas fuertes y bien equipadas como garante de la soberanía y la integridad territorial. Se busca una “suficiencia defensiva” que permita responder a amenazas y cumplir con compromisos internacionales.
Lucha contra el Terrorismo: La lucha contra el terrorismo se presenta como un desafío constante y una prioridad absoluta. Se aboga por una respuesta firme y contundente, tanto a nivel nacional como en colaboración con otros países.
Seguridad Ciudadana: La seguridad ciudadana se vincula directamente con la protección de las libertades y el estado de derecho. Se propone una política de seguridad eficaz y respetuosa con los derechos fundamentales.
Vinculación Seguridad Interior/Exterior: Muchos presidentes reconocen la interdependencia entre la seguridad interior y la exterior, señalando que las amenazas a menudo trascienden las fronteras nacionales.
II. Seguridad Exterior y el Rol de Organizaciones Internacionales:
La seguridad exterior se aborda principalmente a través de la participación en organizaciones internacionales, especialmente la OTAN y la Unión Europea.
OTAN: La OTAN se considera una pieza clave para la defensa colectiva y la disuasión de amenazas. La pertenencia a la Alianza Atlántica se justifica como una necesidad geoestratégica y un compromiso con la seguridad colectiva. Varios presidentes mencionan la importancia de cumplir con los compromisos adquiridos en la OTAN.
Unión Europea: La UE se considera un marco fundamental para la cooperación en materia de seguridad, especialmente en el ámbito de la política común de seguridad y defensa. Se apoya el fortalecimiento de la capacidad de defensa europea y la cooperación con otros países.
FRONTEX: Si bien no se menciona explícitamente en todos los textos, se infiere que la colaboración con organizaciones como FRONTEX (Agencia Europea de la Guardia de Fronteras y Costas) se considera importante para el control de fronteras y la lucha contra la inmigración ilegal y el crimen transnacional. Se percibe como una herramienta para garantizar la seguridad interior y la protección de las fronteras.
Diplomacia y Cooperación Internacional: Además de la participación en organizaciones internacionales, se enfatiza la importancia de la diplomacia y la cooperación con otros países para la resolución pacífica de conflictos y la promoción de la seguridad internacional.
III. Evolución de las Posiciones:
Si bien existe un consenso general en la importancia de la seguridad, se pueden observar algunas diferencias en las posiciones de los diferentes presidentes:
Énfasis en la Integración Europea: Algunos presidentes ponen un mayor énfasis en la integración europea como un pilar fundamental de la política exterior y de seguridad.
Prioridad de la Defensa Nacional: Otros presidentes resaltan la importancia de una defensa nacional fuerte y autónoma.
Enfoque en la Diplomacia: Algunos presidentes priorizan la diplomacia y la cooperación internacional como herramientas para la resolución de conflictos y la promoción de la seguridad.
IV. Temas Recurrentes:
Coordinación y Consenso: Varios presidentes abogan por una política exterior y de seguridad basada en el consenso y la coordinación entre los diferentes actores políticos y sociales.
Adaptación a Nuevas Amenazas: Se reconoce la necesidad de adaptar las políticas de seguridad a las nuevas amenazas, como el terrorismo, la ciberdelincuencia y la inmigración ilegal.
Cultura de Seguridad Nacional: Algunos presidentes proponen impulsar una cultura de seguridad nacional que involucre a todos los ciudadanos en la defensa del país.
En resumen, los presidentes españoles analizados comparten una visión general de la seguridad como un pilar fundamental para la estabilidad y el desarrollo del país. La participación en organizaciones internacionales como la OTAN y la UE se considera esencial para la defensa de los intereses nacionales y la promoción de la seguridad colectiva. Si bien existen algunas diferencias en las posiciones de los diferentes presidentes, existe un consenso general en la importancia de una política exterior y de seguridad basada en el consenso, la coordinación y la adaptación a las nuevas amenazas.
Extracción de datos
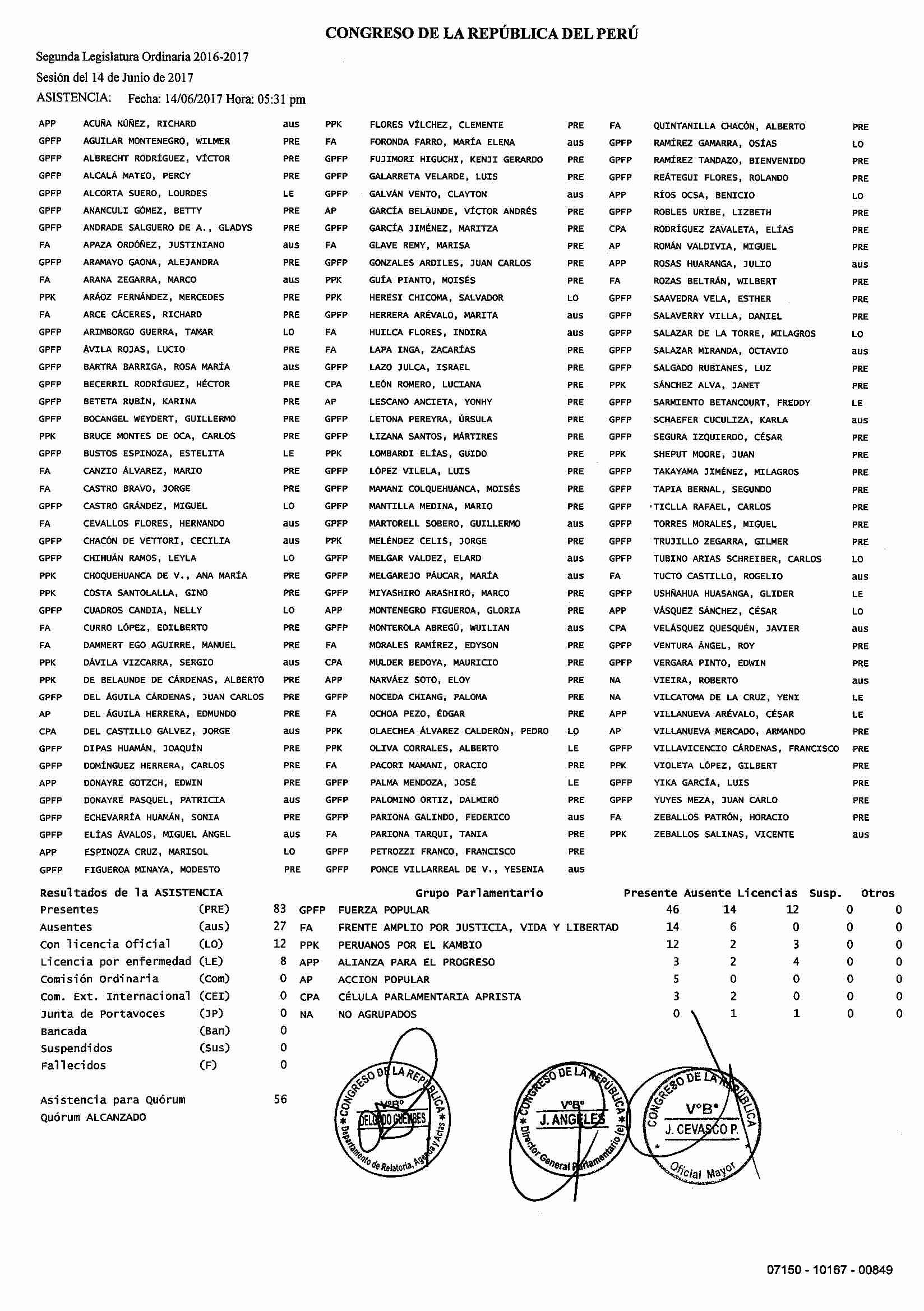
Otro uso que podemos dar a los modelos de IA es la extracción de datos de textos. En muchos casos, los datos que necesitamos están en textos que no están estructurados o que resultan difíciles de extraer de forma organizada. Por ejemplo, en el caso de las actas de reuniones, los informes de asistencia o los resúmenes de eventos, los datos pueden estar dispersos y ser difíciles de analizar. Los modelos LLM pueden ayudarnos a convertir esos datos en tablas o bases de datos que podamos analizar con mayor facilidad.
La figura abajo contiene un listado de asistencia de la sesión plenaria del Congreso de Perú llevada a cabo el 14 de junio de 2017. En total, el documento contiene 9 páginas de asistencia y otras 9 conteniendo votaciones. Infelizmente, el pdf está escaneado y solo podemos acceder a imágenes. Como tarea previa, he llevado a cabo el reconocimiento de caracteres (OCR). Pero aún así, hace falta convertir los datos en una tabla que podamos analizar.
Como podemos ver, el acta de asistencia está organizado en tres grandes bloques. El primero es la identificación de la sesión, con la fecha, la hora y el período legislativo. El segundo apartado se divide en tres columnas con el grupo parlamentario, los apellidos y los nombres de los diputados y el tipo de asistencia. El bloque final contiene los datos agregados. Nos interesa extraer los datos del segundo bloque y convertirlos en un data.frame.
El primer paso consiste en cargar los textos de asistencia extraidos del pdf original. Ya he creado un objeto RData con los textos que podemos descargar de la nube.
Código
library(readr)library(stringi)library(readtext)library(httr)# Carga los datos de texto almacenados # en la nuberesponse <-GET(url="https://github.com/rodrodr/cieps2025/raw/ccadffc3bbf8f510ae013278336da8a441bf2c0d/asistencias.RData")# Los guarda en el ordenadorwriteBin(response$content, "asistencia.Rdata")# Carga el archivoload("asistencia.Rdata")
Ahora pasamos a la extracción de los datos de los textos. Como en los ejemplos anteriores, he preparado un par de ejemplos para que el modelo pueda identificar qué quiero que extraiga y en qué formato. De forma más concreta, he pedido que separe los datos de un mismo diputado con un punto y coma y que se separen las columnas con un salto de línea.
El modelo elegido ha sido el gemma2:2b, pequeño y rápido, especialmente indicado para grandes volúmenes de texto. Para aumentar la precisión y velocidad, he aislado el segundo bloque con los nombres y, luego, dividi el texto por líenas. De ese modo, en lugar de tener que procesar todos los nombres a la vez, lo hace de forma secuencial, línea a línea (y página a página).
El prompt también lleva en cuenta la tarea a llevar a cabo, la extracción de datos, la estructura de la información, las posibilidades de identificación de los diferentes tipos de ausencia.
Código
# Crea un conjunto de ejemplos# para extraer los datoseje <-tribble(~text, ~answer,"APP ACUÑA NUÑEZ, RICHARD aus PPK FLORES VÍLCHEZ, CLEMENTE PRE FA QUINTANILLA CHACÓN, ALBERTO PRE","APP;ACUÑA NUÑEZ, RICHARD;AUS\nPPK;FLORES VÍLCHEZ, CLEMENTE;PRE\nFA;QUINTANILLA CHACÓN, ALBERTO;PRE","GPFP AGUILAR MONTENEGRO, WILMER PRE FA FORONDA FARRO, MARÍA ELENA aus GPFP RAMÍREZ GAMARRA, OSÍAS LO","GPFP;AGUILAR MONTENEGRO, WILMER;PRE\nFA;FORONDA FARRO, MARÍA ELENA;aus\nGPFP;RAMÍREZ GAMARRA, OSÍAS ;LO","GPFP FIGUEROA MINAYA, MODESTO PRE GPFP PONCE VILLARREAL DE V., YESENIA aus","GPFP;FIGUEROA MINAYA, MODESTO;PRE\nGPFP;PONCE VILLARREAL DE V., YESENIA;aus")# Elije el modelomodelo <-"gemma2:2b"# Crea un conjunto de datos vacío# para acumular los resultadosd <-data.frame()# Para cada archivo de texto# (por temas de tiempo, solo se# procesarán los primeros 2)for(i in1:2){# Lee las líneas del texto ll <-read_lines(tx$text[i])# Encuentra la seccion del # texto que contiene la información nn <-which(stri_detect_fixed(ll, "ASISTENCIA")==TRUE)# Extrae la sección del texto# deseada ll <- ll[(nn[1]+1):(nn[2]-1)]# Crea una consulta q <-make_query(template ="{text}\n{prompt}",text = ll,prompt ="Utilizando las instrucciones anteriores como referencia, retorna una tabla con tres variables -grupo, diputado, status- separada por ; con los datos del texto para devolver solo la tabla con los datos extraídos: Grupo;diputado;status. OUTPUT: grupo;diputado;status",system ="Eres un modelo experto en extracción de atributos de un texto. A continuación se le proporciona un texto con informaciones sobre personas que han asistido a los plenos de debates del congreso de diputados de Perú. Los nombres se encuentran divididos en tres columnas. La información de cada diputado aparece como GRUPO APELLIDOS, NOMBRES STATUS, donde Grupo es el grupo parlamentario a que pertenece, Apellidos son los apellidos de la persona en cuestión, Nombres contiene los nombres de la persona y STATUS corresponde si ha estado presente (PRE), ausente (aus) o licenciado (LO/LE), fallecido (F), en la Junta de Portavoces (JP). NUNCA introduzca comentarios más allá del formato de salida deseado.",examples = eje)# Realiza la consulta out <-query(q, model = modelo, screen = F, output ="data.frame",verbose = F,model_params =list(seed=123,temperature=0))# Convierte la salida en un data.frame la <-paste(out$response, collapse="\n") la <-read_delim(la, delim=";", col_names = F,show_col_types=F)# Añade el id del documento la$doc <- tx$doc_id[i]# Acumula los resultados d <-rbind(d, la)}# Muestra los resultadosreactable(d, sortable = T, resizable = T)
Como vemos, el modelo ha sido capaz de identificar 260 observaciones para tres variables, 130 para cada uno de los dos textos. Esa información ya está lista para ser analizada. Le he añadido también el nombre del archivo original, que me permite identificar a qué sesión, fecha y documento .pdf pertenece cada asistencia.
Análisis de datos
También podemos pedir a los modelos de IA que realice análisis de datos. En el código a continuación, utilizamos una base de datos sobre los países del mundo contenida en el paquete poliscidata (con datos de Pollock and Edwards, an R Companion to Essentials of Political Analysis) para pedir que el modelo interprete los datos y el resultado de correlaciones -entre democracia y fraccionamiento étnico, por ejemplo- y un teste t de Student de la media en el índice de democratización entre países de mayoría musulmana y no musulmana. Se tratan de relaciones complejos y que representan retos para cualquier analista, no solo una IA. Veamos los resultados:
Código
# Carga el paquete con los datoslibrary(poliscidata)# Prepara los datosw <- worldw <- w[, c("country","dem_level4", "dem_score14", "frac_eth", "muslim", "pop_65_older")]names(w) <-c("Country", "Democracy_Level", "Democracy_Score", "Ethnic_Fractionalization", "Muslim_Majority", "Population_65_and_Older")# Transforma en una tabla de textowt <- knitr::kable(w)wt <-paste0(wt, collapse="\n")# Genera las correlacionesco <-round(cor(w[,c("Democracy_Score", "Ethnic_Fractionalization","Population_65_and_Older")], use ="pairwise.complete.obs", method ="pearson"),3)# Transforma en una tabla de textoco <- knitr::kable(co)co <-paste0(co, collapse="\n")# Ejecuta el test t de Studenttt <-t.test(w$Democracy_Score~w$Muslim_Majority, conf.level=0.99)tt <-paste0(tt, collapse="\n")# Crea el promptprompt <-paste0("Actúa como un analista de datos de las ciencias sociales. Tu tarea consiste en analizar dos tablas con datos. La primera tabla contiene información nivel de democracia, el índice de democracia, la diversidad étnica, si la mayoría de la población es musulmana y el porcentaje de la población con 65 años o más en diversos países. Los datos de la tabla son los siguientes: \n\n",wt, "\n\n y la tabla de correlaciones entre el índice de democracia, la fracionalización étnica y el porcentaje de personas con 65 años o más es la siguiente: \n\n", co, ".\n\nLos resultados del teste t de diferencia entre medias entre el índice de democracia y si el país posee una mayoría musulmana es el siguiente: \n\n", tt,"\n\n. Con base en esos datos: \n\n1) realiza un análisis descriptivo de las variables; 2) realiza un análisis entre nivel de democracia y diversidad étnica; 3) realiza un análisis entre el índice de democracia y la mayoría musulmana; y, finalmente, 4) realiza un análisis entre el mayoría musulmana y la diversidad étnica.\n\nUna vez realizo el análisis, escribe una síntesis de unas 2000 palabras sobre el tema.")# Ejecuta el modelolibrary(ellmer)model <-"gemini-2.5-flash-preview-05-20"chat <-chat_gemini(base_url ="https://generativelanguage.googleapis.com/v1beta/",api_args =list(generationConfig =list(temperature=1, seed=1234)), model = model, echo="none")out <- chat$chat(prompt)# Devuelve la respuestacat(out)
¡Excelente! Como analista de datos de las ciencias sociales, abordaré esta tarea con una perspectiva crítica y cautelosa, reconociendo la complejidad inherente a los fenómenos sociales y políticos. Procederé con el análisis descriptivo, seguido de los análisis bivariados solicitados, y finalmente, una síntesis comprensiva.
Análisis de Datos: Democracia, Diversidad Étnica y Mayoría Musulmana
Introducción
El presente análisis explora las interrelaciones entre el nivel de democracia, la diversidad étnica, la presencia de una mayoría musulmana y la estructura demográfica (porcentaje de población mayor de 65 años) en una muestra de países. Utilizaremos los datos proporcionados para identificar patrones, correlaciones y diferencias significativas, siempre con la cautela necesaria que exige la investigación social, donde la causalidad es difícil de establecer y múltiples factores interactúan.
Las variables clave son: * Democracy_Level: Nivel cualitativo de democracia (Autoritario, Híbrido, Democracia Parcial, Democracia Plena). * Democracy_Score: Índice cuantitativo de democracia. * Ethnic_Fractionalization: Índice de fragmentación étnica (cuanto más alto, mayor diversidad). * Muslim_Majority: Variable binaria que indica si la mayoría de la población es musulmana (Sí/No). * Population_65_and_Older: Porcentaje de la población con 65 años o más.
1. Análisis Descriptivo de las Variables
Comencemos por comprender la distribución y características básicas de cada variable en el conjunto de datos.
Democracy_Level: Esta variable categórica nos muestra la distribución de los países según su nivel de democracia: * Autoritario: 56 países * Híbrido: 37 países * Democracia Parcial (Part Democ): 46 países * Democracia Plena (Full Democ): 24 países
Observamos una distribución relativamente equilibrada entre los distintos niveles, con una ligera preponderancia de regímenes autoritarios, lo que refleja la realidad geopolítica actual. La existencia de un número considerable de “democracias parciales” e “híbridos” subraya la complejidad y la naturaleza transicional de muchos sistemas políticos.
Democracy_Score: Este índice numérico proporciona una medida más granular de la democracia. * Media: Aproximadamente 5.06 * Desviación Estándar: Aproximadamente 2.12 * Mínimo: 1.08 (Corea del Norte) * Máximo: 9.93 (Noruega)
El rango amplio (casi 9 puntos) indica una gran variabilidad en el nivel de democracia entre los países de la muestra, desde los regímenes más represivos hasta las democracias más consolidadas. La media de 5.06 sugiere que el “país promedio” en esta muestra se encuentra en el rango de un régimen híbrido o una democracia parcial baja, lo cual es coherente con la distribución observada en Democracy_Level.
Ethnic_Fractionalization: Este índice mide la probabilidad de que dos individuos elegidos al azar de un país pertenezcan a diferentes grupos étnicos. * Media: Aproximadamente 0.49 * Desviación Estándar: Aproximadamente 0.25 * Mínimo: 0.00 (Comoras) * Máximo: 0.93 (Uganda) * Valores NA: 17 países tienen datos faltantes.
La media de 0.49 sugiere que, en promedio, hay una probabilidad cercana al 50% de que dos individuos aleatorios en un país dado sean de etnias diferentes. El rango desde 0 (Comoras, aunque esto podría indicar una homogeneidad extrema o una clasificación particular de su población) hasta 0.93 (Uganda) muestra una vasta diferencia en la diversidad étnica globalmente. La presencia de 17 valores faltantes (NA) es una limitación que debe tenerse en cuenta, ya que estos países se excluyen de los análisis que utilizan esta variable.
Muslim_Majority: Esta variable binaria es crucial para comprender el impacto de la religión mayoritaria. * No (Mayoría no musulmana): 122 países * Sí (Mayoría musulmana): 45 países
La muestra contiene una proporción significativamente mayor de países donde la mayoría de la población no es musulmana. Esta disparidad en el tamaño de los grupos es importante para interpretar los resultados de pruebas estadísticas.
Population_65_and_Older: Este porcentaje refleja la estructura demográfica de los países. * Media: Aproximadamente 8.3% * Desviación Estándar: Aproximadamente 5.1% * Mínimo: 0.9% (Emiratos Árabes Unidos) * Máximo: 22.9% (Japón) * Valores NA: 2 países tienen datos faltantes (Burma y Palestine).
El rango es amplio, desde menos del 1% en EAU (un país con una gran población de trabajadores jóvenes inmigrantes) hasta casi el 23% en Japón (una de las sociedades más envejecidas del mundo). La media del 8.3% sugiere una población globalmente relativamente joven, aunque con una considerable variación. El envejecimiento de la población es a menudo un indicador de desarrollo económico y social, lo que sugiere una posible correlación con el nivel de democracia.
Resumen Descriptivo: El conjunto de datos presenta una imagen diversa de países en términos de sus niveles de democracia, diversidad étnica y estructuras demográficas. Las variables numéricas muestran rangos considerables, lo que permite observar variaciones significativas. La presencia de valores faltantes en algunas variables es una consideración metodológica.
2. Análisis entre Nivel de Democracia y Diversidad Étnica
Para analizar la relación entre Democracy_Level (categórica) y Ethnic_Fractionalization (numérica), podemos complementar la información de la tabla de correlaciones con una observación de las medias de Ethnic_Fractionalization para cada nivel de democracia (aunque no se proporcionan directamente, la correlación de Democracy_Score es un buen proxy).
Correlación entre Democracy_Score y Ethnic_Fractionalization: La tabla de correlaciones muestra un coeficiente de correlación de -0.394 entre Democracy_Score y Ethnic_Fractionalization.
Interpretación: * Dirección Negativa: Un coeficiente negativo indica que, a medida que la fragmentación étnica (Ethnic_Fractionalization) aumenta, el Democracy_Score tiende a disminuir. En otras palabras, los países con mayor diversidad étnica, en promedio, tienden a tener puntuaciones de democracia más bajas, lo que se traduce en niveles de democracia más cercanos a “Híbrido” o “Autoritario”. * Magnitud Moderada: Un valor de -0.394 se considera una correlación moderada. No es una relación extremadamente fuerte, lo que significa que la diversidad étnica no es el único ni el principal factor determinante de la democracia, pero sí un factor que se asocia con ella de manera significativa.
Implicaciones en las Ciencias Sociales: Esta correlación sugiere que la alta diversidad étnica puede presentar desafíos para la consolidación y el funcionamiento de las instituciones democráticas. Algunas explicaciones planteadas en la literatura incluyen: * Polarización y Conflicto: En sociedades altamente fragmentadas, las líneas de división étnica pueden superponerse con las políticas, llevando a una mayor polarización, menor consenso y, en casos extremos, a conflictos civiles o inestabilidad política que dificultan el desarrollo democrático. * Dificultades en la Construcción de Instituciones: La construcción de un Estado de derecho imparcial, una burocracia meritocrática y mecanismos de distribución equitativa de recursos puede ser más compleja en ausencia de una identidad nacional cohesionada. * Gobiernos Rentistas y Exclusivos: En algunos contextos, las élites de un grupo étnico dominante pueden buscar mantener el poder de manera autoritaria para preservar sus privilegios, excluyendo a otros grupos.
Sin embargo, es crucial recordar que esta es una correlación y no implica causalidad directa. Existen numerosas “democracias plenas” y “parciales” que son altamente diversas étnicamente (por ejemplo, Canadá, India, Sudáfrica, Australia, si bien su índice de fragmentación es menor que el de algunos países africanos). En estos casos, la fortaleza de las instituciones, la cultura política de tolerancia, los mecanismos de representación inclusiva y el desarrollo económico pueden mitigar los desafíos de la diversidad. Por el contrario, muchos países étnicamente homogéneos también son autoritarios.
El análisis de Democracy_Level directamente implicaría examinar las medias de Ethnic_Fractionalization para cada categoría (Autoritario, Híbrido, etc.). Aunque no se proporcionan, se esperaría que los países “Autoritarios” y “Híbridos” tuvieran, en promedio, índices de fragmentación étnica más altos que las “Democracias Plenas”, en línea con la correlación observada con Democracy_Score.
3. Análisis entre el Índice de Democracia y la Mayoría Musulmana
Para este análisis, se nos ha proporcionado el resultado de un test t de diferencia entre medias (Welch Two Sample t-test), comparando los Democracy_Score de países con y sin una mayoría musulmana.
Resultados del Test t: * Estadístico t: 8.69076461000291 * Grados de libertad (df): 120.77141729791 * Valor p: 2.10442008073389e-14 (equivalente a \(2.1 \times 10^{-14}\), un número extremadamente pequeño) * Media del grupo ‘No’ (países no musulmanes): 6.21 * Media del grupo ‘Yes’ (países musulmanes): 3.80673913043478 (aproximadamente 3.81) * Intervalo de Confianza (95%): (1.67953884228739, 3.12698289684304) para la diferencia de medias.
Interpretación:
Hipótesis:
Hipótesis Nula (\(H_0\)): No hay diferencia significativa en el Democracy_Score promedio entre países con y sin una mayoría musulmana.
Hipótesis Alternativa (\(H_1\)): Sí existe una diferencia significativa en el Democracy_Score promedio entre ambos grupos.
Significancia Estadística: El valor p (\(2.1 \times 10^{-14}\)) es extraordinariamente bajo, muy inferior a cualquier umbral de significancia común (e.g., 0.05, 0.01, 0.001). Esto nos permite rechazar contundentemente la hipótesis nula.
Magnitud y Dirección de la Diferencia:
La media del Democracy_Score para países con una mayoría no musulmana es de 6.21.
La media del Democracy_Score para países con una mayoría musulmana es de 3.81.
La diferencia en las medias es de aproximadamente \(6.21 - 3.81 = 2.40\).
El intervalo de confianza para esta diferencia (1.68 a 3.13) no incluye el cero, lo que refuerza la significancia de la diferencia observada.
Esto significa que, en nuestra muestra de datos, los países donde la mayoría de la población es musulmana exhiben, en promedio, puntuaciones de democracia significativamente más bajas que los países donde la mayoría de la población no es musulmana. La magnitud de esta diferencia (aproximadamente 2.4 puntos en el índice de democracia) es considerable.
Análisis Crítico y Consideraciones Adicionales:
Este es un hallazgo estadísticamente robusto, pero su interpretación en las ciencias sociales requiere una gran cautela para evitar conclusiones simplistas o esencialistas.
Correlación vs. Causalidad: Es vital reiterar que esta es una correlación. El hecho de que un país tenga una mayoría musulmana no causa inherentemente un menor nivel de democracia. La religión es un factor complejo, y su interacción con la política está mediada por innumerables variables históricas, culturales, socioeconómicas y geopolíticas.
Factores Concomitantes: Muchos países con mayoría musulmana, especialmente en la región de Oriente Medio y el Norte de África, comparten características históricas y estructurales que pueden ser más influyentes en sus trayectorias democráticas:
Legados Coloniales: Algunos experimentaron legados coloniales que dejaron instituciones débiles o regímenes autoritarios.
Riqueza Petrolera (Estados Rentistas): La presencia de recursos naturales como el petróleo puede permitir a los regímenes mantener el control a través de la cooptación de la población y sin necesidad de rendir cuentas a través de mecanismos democráticos (la “maldición de los recursos”). Muchos de los países musulmanes con menor puntuación democrática (ej., Arabia Saudita, Kuwait, EAU, Qatar) son también Estados rentistas.
Conflicto y Estabilidad Regional: La región en general ha sido escenario de alta inestabilidad, conflictos y, en algunos casos, intervención externa, lo que puede priorizar la estabilidad sobre la democratización.
Desarrollo Socioeconómico: Muchos países de mayoría musulmana son países en desarrollo, y existe una correlación conocida entre desarrollo económico, educación y democratización.
Interpretaciones del Islam: Si bien hay interpretaciones del Islam que son compatibles con la democracia, también existen corrientes conservadoras o fundamentalistas que pueden ser más proclives a formas de gobierno autoritarias o teocráticas. Sin embargo, no se puede generalizar al “Islam” como una barrera monolítica a la democracia, ya que hay ejemplos de democracias funcionales con mayorías musulmanas (ej., Indonesia, Malasia, Albania, Senegal, Bosnia, Túnez - aunque Túnez ha retrocedido recientemente).
Diversidad dentro del Grupo: El grupo de países con mayoría musulmana es diverso. Incluye desde la “Democracia Parcial” de Indonesia y Túnez, hasta los “Autoritarios” de Arabia Saudita y Corea del Norte (que no es musulmán pero tiene un score similar). Las medias ocultan esta heterogeneidad.
Influencia de Otros Factores: Otros factores como la diversidad étnica (como vimos en el punto anterior) y la estructura demográfica (porcentaje de población mayor de 65 años, que se correlaciona positivamente con democracia) también juegan un papel, y su interacción con la mayoría musulmana debería ser explorada en modelos multivariados.
En resumen, los datos revelan una asociación estadística significativa entre una mayoría musulmana y puntuaciones de democracia más bajas. Sin embargo, es crucial ir más allá de esta correlación superficial y considerar el complejo entramado de factores históricos, económicos, políticos y culturales que configuran la trayectoria democrática de estas naciones.
4. Análisis entre Mayoría Musulmana y Diversidad Étnica
Para analizar la relación entre Muslim_Majority (categórica binaria) y Ethnic_Fractionalization (numérica), calcularemos las medias de fragmentación étnica para ambos grupos de países. Dado que no se proporciona un test t específico para esta relación, realizaremos el cálculo de las medias a partir de la tabla original de datos.
Cálculo de las Medias de Ethnic_Fractionalization por Grupo:
Para los países con datos completos sobre Ethnic_Fractionalization: * Países con Mayoría Musulmana (‘Yes’): * Número de países con datos de EF: 38 * Suma de Ethnic_Fractionalization para estos países: 21.0543 * Media de Ethnic_Fractionalization (Mayoría Musulmana):\(21.0543 / 38 \approx **0.554**\)
Países sin Mayoría Musulmana (‘No’):
Número de países con datos de EF: 112
Suma de Ethnic_Fractionalization para estos países: 50.8415
Media de Ethnic_Fractionalization (No Mayoría Musulmana):\(50.8415 / 112 \approx **0.454**\)
Interpretación:
Observamos que los países con una mayoría musulmana en la muestra tienen, en promedio, un índice de fragmentación étnica ligeramente más alto (0.554) que los países sin una mayoría musulmana (0.454).
Análisis en Contexto:
Esta diferencia, aunque no evaluada con un test de significancia estadística en este análisis, sugiere una tendencia. Podría indicar que las regiones con predominio musulmán (por ejemplo, partes de África del Norte, Oriente Medio y Asia Central, y el Sudeste Asiático) exhiben una mayor diversidad étnica que otras regiones predominantemente no musulmanas.
Ejemplos de alta diversidad en países musulmanes: Afganistán (0.76), Burkina Faso (0.73), Chad (0.86), Indonesia (0.73), Malasia (0.67), Nigeria (0.85), Sudán (0.71).
Ejemplos de baja diversidad en países musulmanes: Comoras (0.00), Bangladesh (0.04), Túnez (0.039), Albania (0.22).
Es importante considerar que la diversidad étnica es un rasgo geográfico e histórico, no directamente vinculado a una religión. Sin embargo, los patrones migratorios históricos, la formación de estados multiétnicos y las dinámicas coloniales en diversas regiones del mundo donde el Islam es predominante, pueden haber contribuido a estos niveles de fragmentación.
Esta observación, combinada con los hallazgos anteriores, complejiza la imagen. Si los países con mayoría musulmana tienden a ser menos democráticos y ligeramente más diversos étnicamente, esto podría sugerir una interacción de factores. Es decir, la presencia de una mayoría musulmana podría coincidir con regiones de mayor diversidad étnica, y si la diversidad étnica plantea desafíos para la democracia (como sugiere la correlación negativa en el punto 2), entonces ambas variables podrían contribuir, de forma interrelacionada, a las puntuaciones democráticas observadas. Sin embargo, esto requeriría un análisis multivariado más profundo para desentrañar la influencia relativa de cada factor.
Síntesis Amplia: Entendiendo los Determinantes de la Democracia
La democracia, en sus diversas formas y grados, sigue siendo un objeto de estudio central en las ciencias sociales. Los datos proporcionados ofrecen una instantánea valiosa de cómo ciertos factores demográficos y sociopolíticos, como la diversidad étnica, la composición religiosa de la población y la estructura de edad, se asocian con los niveles de democratización en una muestra global de países. El análisis descriptivo inicial ya subraya la heterogeneidad del paisaje político mundial, desde autocracias consolidadas hasta democracias plenas. La variabilidad en los índices de democracia, diversidad étnica y envejecimiento poblacional nos invita a buscar patrones y explicaciones, aunque siempre con la conciencia de que las relaciones sociales son multicausales y raramente simples.
La Democracia y el Desafío de la Diversidad Étnica
Uno de los hallazgos más consistentes en el análisis de las correlaciones es la relación entre el índice de democracia (Democracy_Score) y la fragmentación étnica (Ethnic_Fractionalization). La correlación de -0.394 es negativa y de magnitud moderada, lo que implica que, en promedio, los países con una mayor diversidad étnica tienden a exhibir puntuaciones de democracia más bajas. Esta observación no es ajena a la literatura académica, que ha explorado durante décadas los desafíos que la heterogeneidad social puede plantear a la cohesión y gobernabilidad democráticas.
En sociedades con alta fragmentación étnica, la construcción de un consenso político puede ser más ardua. Las identidades étnicas a menudo se convierten en la base de la movilización política, lo que puede llevar a una mayor polarización, menor confianza intergrupal y dificultades para establecer instituciones políticas que sean percibidas como imparciales y representativas de todos los segmentos de la sociedad. En un contexto de recursos escasos, las divisiones étnicas pueden agravar la competencia y el clientelismo, debilitando el Estado de derecho y fomentando la corrupción. Además, la historia demuestra que la falta de inclusión política de ciertos grupos étnicos puede ser un caldo de cultivo para la inestabilidad, la violencia y, en última instancia, el retroceso democrático. La capacidad de un estado para gestionar la diversidad a través de mecanismos de federalismo, representación proporcional, autonomía cultural y políticas de no discriminación se vuelve crucial para el éxito democrático en contextos multiétnicos. Sin embargo, cabe destacar que la correlación moderada también significa que la diversidad étnica no es un destino ineludible para la no democracia; el caso de Canadá, India, y Sudáfrica (aunque este último es una “democracia parcial” en la tabla, ha avanzado significativamente) son ejemplos de naciones multiétnicas que han navegado, con diversos grados de éxito, las complejidades de la diversidad dentro de marcos democráticos. La resiliencia institucional y la voluntad política para construir puentes interétnicos son tan importantes como la presencia misma de la diversidad.
El Islam y el Índice de Democracia: Una Perspectiva Matizada
Quizás el hallazgo más llamativo y que exige la interpretación más cuidadosa es la relación entre el índice de democracia y la mayoría musulmana (Muslim_Majority). El test t de Welch proporciona una evidencia estadística abrumadora: los países con una mayoría musulmana tienen un Democracy_Score promedio significativamente más bajo (aproximadamente 3.81) en comparación con los países sin una mayoría musulmana (aproximadamente 6.21). La diferencia de casi 2.4 puntos en el índice de democracia es sustancial y altamente significativa, con un valor p que es prácticamente cero (\(2.1 \times 10^{-14}\)).
Esta diferencia, aunque estadísticamente irrefutable en esta muestra, no debe ser interpretada como una declaración de que el Islam, como religión, sea inherentemente incompatible con la democracia. Tal conclusión sería una simplificación excesiva y una falacia ecológica. Las ciencias sociales nos enseñan que las trayectorias políticas de las naciones son producto de un complejo entrelazamiento de factores históricos, económicos, culturales y geopolíticos, y no pueden reducirse a una única variable religiosa.
Múltiples factores contextuales pueden explicar esta correlación observada: * Legados Históricos y Geopolíticos: Muchos de los países con mayoría musulmana se encuentran en regiones que han experimentado historias de colonialismo, conflictos post-coloniales, intervenciones extranjeras y la consolidación de regímenes autoritarios durante la Guerra Fría. La estabilidad regional, a menudo priorizada por las potencias externas o las élites internas, ha tendido a favorecer el autoritarismo sobre la democratización. * Economías Rentistas: Un número considerable de países musulmanes se encuentran en el Medio Oriente, una región rica en petróleo y gas. La “maldición de los recursos naturales” sugiere que los gobiernos que dependen de las rentas de los recursos en lugar de los impuestos de sus ciudadanos tienen menos incentivos para rendir cuentas o desarrollar instituciones democráticas. Pueden “comprar” la lealtad social a través de subsidios y servicios, en lugar de permitir la participación política. * Factores Socioeconómicos: Muchos países de mayoría musulmana son economías en desarrollo con niveles de educación y urbanización que, en promedio, pueden ser más bajos que en las democracias consolidadas. Existe una vasta literatura que correlaciona el desarrollo socioeconómico con la democratización (la teoría de la modernización). * Culturas Políticas Específicas: Si bien el Islam es una religión diversa con múltiples interpretaciones, en algunas regiones predominan corrientes conservadoras o autoritarias que han influido en las estructuras de gobierno. Sin embargo, esto no es universal; ejemplos como Indonesia, el país musulmán más poblado y una democracia parcial, o Albania, una democracia híbrida en el camino hacia la plena democracia, demuestran que las poblaciones de mayoría musulmana pueden coexistir con sistemas políticos democráticos. La clave no es la religión en sí, sino las interpretaciones culturales, el papel de las instituciones religiosas en la política y la capacidad de las élites para adaptarse a los principios democráticos.
En definitiva, la correlación es un llamado a la investigación más profunda, no a una conclusión simplista. Se requieren estudios cualitativos y cuantitativos que controlen por múltiples variables para desentrañar los mecanismos subyacentes a esta observación.
Mayoría Musulmana y Diversidad Étnica: Explorando la Intersección
Aunque el análisis no incluyó un test t para esta relación, el cálculo de las medias revela una tendencia interesante: los países con una mayoría musulmana en nuestra muestra tienen una media de Ethnic_Fractionalization de aproximadamente 0.554, mientras que los países sin mayoría musulmana tienen una media de 0.454. Esto sugiere que, en promedio, los países musulmanes en esta muestra son ligeramente más diversos étnicamente.
Esta observación podría tener implicaciones indirectas para la democracia. Si, como se observó en el punto 2, una mayor diversidad étnica se asocia con menores puntuaciones de democracia, y si los países con mayoría musulmana son también, en promedio, más diversos étnicamente, entonces la “mayoría musulmana” podría estar actuando, en parte, como un indicador de un contexto de mayor diversidad étnica que presenta desafíos a la gobernabilidad democrática. Sin embargo, esta es una hipótesis que requeriría un análisis multivariado para determinar si la diversidad étnica explica parte de la variación en la democracia asociada a la mayoría musulmana, o si ambas variables operan de forma independiente o incluso interactúan.
Es crucial reconocer que la diversidad étnica en países musulmanes no es uniforme; hay países muy homogéneos como Túnez o Albania, y otros extremadamente diversos como Nigeria o Indonesia. Este hallazgo subraya la necesidad de evitar la homogeneización de la “mayoría musulmana” como categoría, ya que abarca una vasta gama de experiencias sociopolíticas y demográficas.
La Democracia y la Estructura Demográfica: La Población Envejecida
Finalmente, el análisis de correlaciones también revela un vínculo con la población mayor de 65 años (Population_65_and_Older). Existe una fuerte correlación positiva de 0.674 entre el Democracy_Score y el porcentaje de población mayor de 65 años. Esto significa que los países con una mayor proporción de población anciana tienden a tener índices de democracia más altos.
Esta correlación es probable un proxy para el nivel de desarrollo económico y social. Las sociedades desarrolladas suelen caracterizarse por sistemas de salud avanzados, baja natalidad y mayor esperanza de vida, lo que conduce a un envejecimiento de la población. Estas mismas sociedades suelen ser también democracias consolidadas, con instituciones estables, altos niveles de educación y fuertes economías. Por lo tanto, el porcentaje de población mayor de 65 años puede ser un indicador de la modernización y la estabilidad que a menudo acompañan a la democratización.
Complementariamente, la correlación negativa de -0.531 entre Ethnic_Fractionalization y Population_65_and_Older es también esclarecedora. Implica que los países con mayor diversidad étnica tienden a tener poblaciones más jóvenes. Esta relación es consistente con la observación de que muchos países altamente diversos son naciones en desarrollo, que a menudo experimentan altas tasas de natalidad y una menor esperanza de vida, resultando en pirámides poblacionales más jóvenes. Por otro lado, las sociedades más homogéneas y desarrolladas (muchas de ellas democracias plenas) suelen tener poblaciones más envejecidas. Esta correlación sugiere una posible vía indirecta: la alta diversidad étnica puede estar asociada con un menor desarrollo, lo que a su vez se asocia con una población más joven y, finalmente, con menores puntuaciones de democracia.
Conclusiones Generales y Direcciones Futuras
En síntesis, este análisis de datos ha revelado varias asociaciones significativas: 1. Menor diversidad étnica se correlaciona con mayores niveles de democracia. 2. Los países con mayoría musulmana exhiben, en promedio, niveles de democracia significativamente más bajos que los países sin mayoría musulmana. 3. Los países con mayoría musulmana tienden a ser ligeramente más diversos étnicamente en esta muestra. 4. Una población más envejecida se correlaciona fuertemente con mayores niveles de democracia y menor diversidad étnica.
Es imperativo subrayar que estos hallazgos son correlacionales. No podemos inferir causalidad directamente de estos datos. La complejidad de los fenómenos sociales y políticos significa que la democracia es el resultado de múltiples factores interactuando de maneras intrincadas. La diversidad étnica puede presentar desafíos a la democracia, pero la capacidad de las instituciones para gestionarla es clave. La asociación de la mayoría musulmana con menores niveles de democracia es un patrón estadístico que requiere un análisis contextual profundo, que tenga en cuenta la historia, la economía política y las dinámicas geopolíticas, más allá de la mera afiliación religiosa. El envejecimiento de la población emerge como un fuerte proxy del desarrollo socioeconómico, que a su vez es un facilitador conocido de la democratización.
Para una comprensión más completa, las futuras investigaciones deberían: * Realizar análisis multivariados (e.g., regresión múltiple) para controlar por la influencia de otras variables y evaluar la contribución independiente de cada factor. * Considerar variables omitidas como el PIB per cápita, el nivel de educación, el legado colonial, la estabilidad institucional, el nivel de conflicto interno, la distribución de la riqueza y la historia de intervenciones externas. * Utilizar datos longitudinales para rastrear los cambios a lo largo del tiempo y establecer relaciones de causalidad más plausibles. * Incorporar estudios de caso cualitativos para proporcionar un contexto rico y comprender los mecanismos causales a nivel micro. * Profundizar en la definición y medición de la “fragmentación étnica” y el “índice de democracia”, reconociendo las limitaciones inherentes a cualquier métrica agregada.
Este análisis exploratorio nos proporciona valiosas pistas y preguntas de investigación, recordándonos que la democracia es un fenómeno frágil y multifacético, modelado por una constelación de fuerzas interconectadas.
Simulación
Otra aplicación de la IA generativa para la investigación consiste en realizar simulaciones. Podemos utilizar la información de entrenamiento para simular expertos y pedir que respondan a preguntas o cuestionarios. Esto resulta útil en dos aspectos centrales. Primero, como forma de sistematizar la información sobre un tema. Segundo, para evaluar la capacidad de los modelos de IA generativa para responder preguntas complejas de forma precisa y coherente.
No exemplo abaixo, utilizamos el modelo Gemini de Google para simular un experto en la República de Weimar. Los modelos LLM suelen ser particularmente buenos cuando se trata de información histórica, puesto que existe una larga literatura sobre el tema y, en algunos casos, parte de esa literatura está disponible en formato digital y en dominio público.
Código
# Carga el paquetelibrary(ellmer)# Define el modelomodel <-"gemini-2.5-flash-preview-04-17"# Crea un objeto chat para# acceder al modelochat <-chat_gemini(base_url ="https://generativelanguage.googleapis.com/v1beta/",api_args =list(generationConfig =list(temperature=0.8, seed=1234)), model = model,echo ="none",system_prompt="Actúa como un historiador político experto en el sistema partidario de la República de Weimar. Responde preguntas y proporciona información sobre los partidos políticos de la República de Weimar. Debe ser preciso y objetivo en sus respuestas, evitando opiniones personales o juicios de valor.")# Define la lista de partidospart <-c("Kommunistische Partei Deutschlands (KPD)","Sozialdemokratische Partei Deutschlands (SPD)","Deutsche Demokratische Partei (DDP)","Deutsche Volkspartei (DVP)","Deutsche Zentrumspartei (Zentrum)","Konservative Volkspartei (KVP)","Nationalsozialistische Deutsche Arbeiterpartei (NSDAP)","Deutsche Demokratische Partei (DDP)","Bayerische Volkspartei (BVP)")# Crea el prompt para la evaluación del# compromiso democrático de los partidosprompt <-paste0("Su tarea consiste en evaluar el nivel de compromiso democrático de los partidos políticos que existieron durante dicho periodo, basándote en evidencia histórica sobre su comportamiento parlamentario, su ideología, sus alianzas políticas y su actitud frente a la Constitución de Weimar y nunca para el período posterior.\n\nUtiliza la siguiente escala para tu evaluación:\n\n0: Completamente antidemocrático (hostil al sistema republicano y parlamentario).\n\n10: Completamente democrático (adhesión plena y activa al sistema republicano y parlamentario).\n\nN.S.: No se puede determinar con certeza.\n\nResponde únicamente con un número del 0 al 10 o con 'N.S.', sin añadir justificaciones ni explicaciones.\n\nPartido a evaluar: ", part,".")# Ejecuta el modeloro <- chat$chat(prompt)# Guarda los resultadosev <-as.numeric(stri_split_fixed(ro, "\n", simplify = T))# Crea otro prompt para evaluar# la ideología de los partidosprompt <-paste0("Su tarea consiste en evaluar la ideología predominante de los partidos políticos en términos de su ubicación en el espectro político de la época, considerando su programa, discursos, acciones políticas, bases sociales y declaraciones oficiales.\n\nUtiliza la siguiente escala para tu evaluación ideológica:\n\n0: Extrema izquierda\n\n10: Extrema derecha\n\nN.S.: No se puede determinar con certeza\n\nResponde únicamente con un número del 0 al 10 o con 'N.S.', sin añadir justificaciones ni explicaciones.\n\n Partido a evaluar: ", part,".")# Ejecuta el modeloro <- chat$chat(prompt)# Guarda los resultadosid <-as.numeric(stri_split_fixed(ro, "\n", simplify = T))# Organiza todo en un# data.framed1 <-data.frame(Partido=part, Democracia=ev, Ideologia=id)# Visualiza los resultadosreactable(d1, sortable=T, resizable=T)